Cross-post Every Eval Ever results to Hugging Face
Send an Every Eval Ever (EEE) record to Hugging Face Community Evals so your score shows up on the model page, with a backlink to the full structured record.
Audience: anyone who reports or reads evaluation results. If you already contribute to Every Eval Ever this is the more technical companion to the stakeholder guides, but first- and third-party evaluators alike can submit.
Why this exists
Every Eval Ever (EEE) launched in February 2026 as a project of the EvalEval Coalition, a cross-institutional effort to fix how AI evaluation results get reported by both first- and third-party evaluators. Hugging Face launched Community Evals the same month to decentralize how benchmark scores get reported on the Hub. Combined, they patch gaps in how users, researchers, and policymakers trust, understand, and choose evaluations and models.
Evaluation results are how we measure model capabilities, compare models against each other, and reason about safety and governance, yet they are scattered and hard to compare. They live in papers, leaderboards, blog posts, and harness logs, each in its own format. The same model on the same benchmark often returns different numbers depending on who ran it and how — LLaMA 65B, for one, has been reported at both 63.7 and 48.8 on MMLU. Gaps like that come from evaluation settings, which only make sense when the metadata is recorded.
EEE is the fix for the reporting side: one JSON schema for an evaluation result that records:
- who ran it
- which model
- how it was accessed
- the generation settings
- what the metric actually means
- (optional) a companion JSONL file for per-sample outputs
The schema was built with feedback from researchers and policy researchers, and it takes in results from any source, so harness logs, leaderboard scrapes, and paper numbers all end up in the same shape. The GitHub repository has the converters, examples, and a contributor guide. Since launching, the datastore on Hugging Face has grown to around 229,000 evaluation results across more than 22,000 models and 2,200 benchmarks, pulled from 31 different reporting formats. Reproducing just those runs from scratch would cost somewhere in the hundreds of thousands of dollars — a reasonable argument for not letting the data scatter once someone has paid to generate it.
What cross-posting does
Contributors can now send EEE results to Hugging Face Community Evals. We built a converter that takes your EEE records and writes the small YAML files Hugging Face expects, so you don't have to keep the same result in two formats by hand.
This is new functionality for everyone who reports or reads evaluations, not only existing EEE contributors. First-party evaluators reporting on their own models and third-party evaluators reporting on someone else's can both submit, to Community Evals and to EEE, and anyone browsing the Hub gets results that trace back to a full record.
Submit your data through your organization's Hugging Face account and your results show up with a verified checkmark on EvalEval — a signal to readers that the numbers come straight from the source.
How Hugging Face Community Evals works with EvalEval
Hugging Face Community Evals has two sides.
- A benchmark lives in a dataset repo that registers itself by adding an
eval.yamldescribing how the benchmark should be run, in the Inspect AI format, so anyone can reproduce it. Once registered, that dataset page collects and displays a leaderboard of every score reported against it across the Hub. The list of official benchmarks grows over time. - A model's scores live in
.eval_results/*.yamlinside the model repo. They show up on the model card and feed into the matching benchmark leaderboard. Both the model author's own results and results submitted by anyone else through a pull request get aggregated, and each score carries a badge saying whether it was author-submitted, community-submitted, or independently verified. Anyone can add a score to any model by opening a PR with the right YAML file, and the model author can close PRs or hide results on their own repo.
You can see one of these leaderboards live on the HLE benchmark dataset.
This is where EEE and Community Evals fit together. When you send a result to both, two things happen:
- Your score appears on the Hugging Face model page and is pulled into the benchmark's leaderboard.
- It carries a source badge that links straight back to the full EEE record, where the generation config, the harness version, the reproducibility notes, and any instance-level data live.
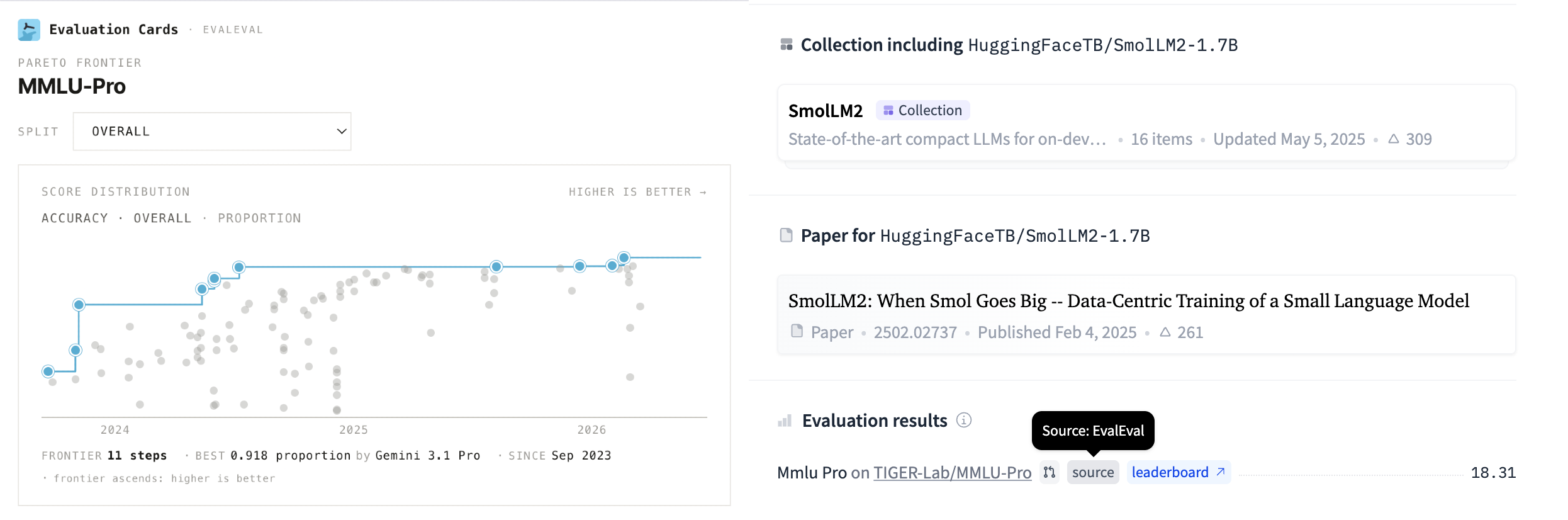
The two destinations do different jobs toward the same goal. Hugging Face puts your result where people look at models, with a link back to the source. EEE keeps the full structured record that makes the result interpretable, and powers Evaluation Cards on top of it. Send your data to both and the same evaluation ends up visible and legible at once, which is the point of reporting one at all.
That cross-compatibility runs the other way too. The same GPQA scores that surface on the model card also render in Evaluation Cards, which composes the EEE run data with benchmark and model metadata into one interpretable record — the same evaluation on a different surface. See the GPQA leaderboard on Evaluation Cards.
How it works
Hugging Face stores eval scores in the model repo, as a YAML file under .eval_results/. The required fields are just the benchmark dataset, the task, and the value. The source block is optional, and it's the part that creates the backlink to EEE.
- dataset:
id: openai/gsm8k
task_id: gsm8k
value: 96.8
date: '2024-07-16'
notes: '8-shot CoT'
source:
url: https://huggingface.co/datasets/evaleval/EEE_datastore/blob/main/flat/objects/<xx>/<yy>/<uuid>.json
name: EvalEval
The converter fills this in from your existing records. It maps:
| EEE field | Hugging Face YAML field |
|---|---|
source_data.hf_repo | dataset.id |
evaluation_name | task_id |
score_details.score | value |
evaluation_timestamp | date |
…then drops in the datastore object URL as the source link to the per-record EEE JSON. It currently handles four of the official benchmarks: MMLU-Pro, GPQA, HLE, and GSM8K.
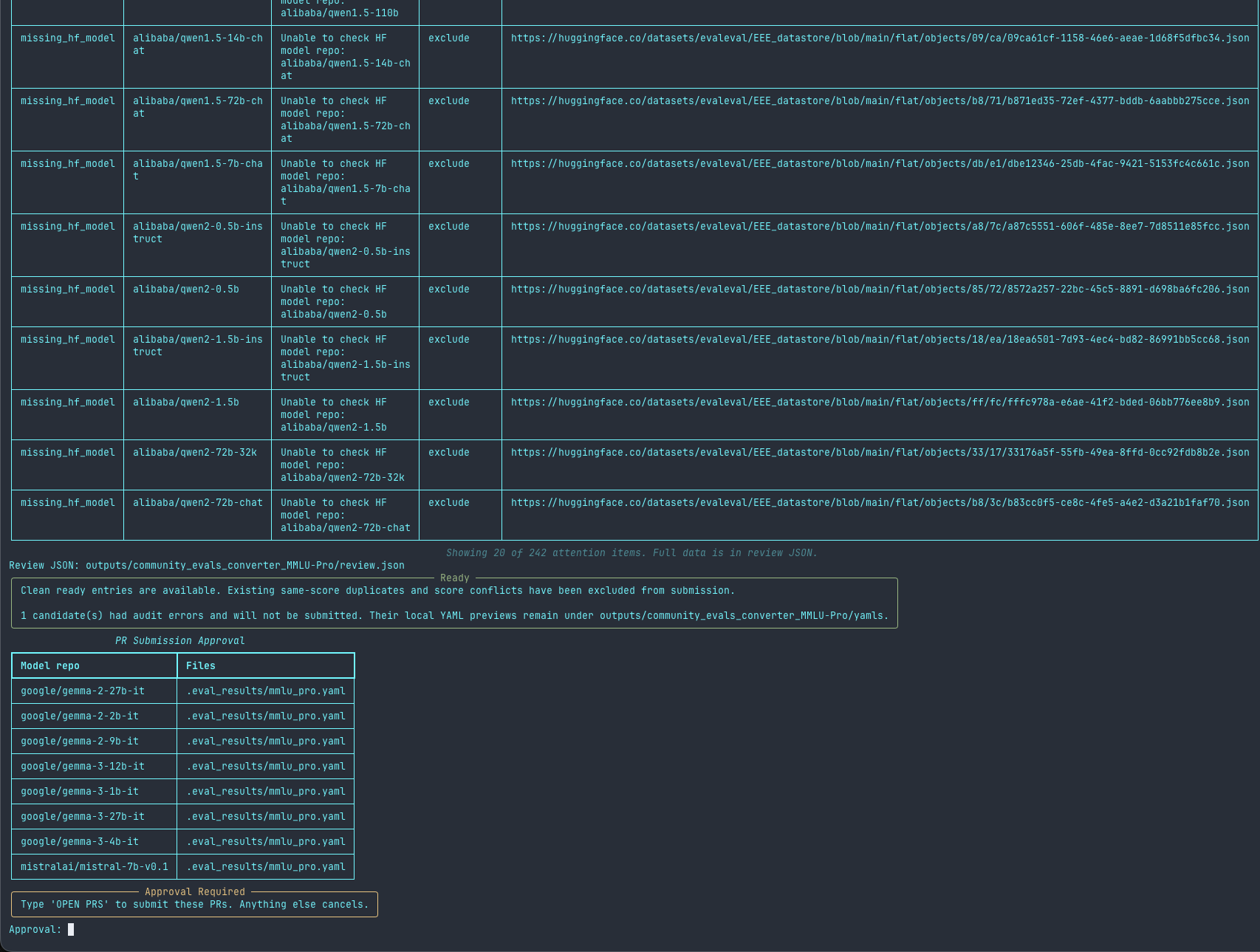
The converter does more than reshape fields. You point it at one EEE datastore collection and it downloads that collection along with the records it references, checks the object hashes, and finds the scores that map to a supported benchmark. Before it writes anything live it audits what already exists: it reads every .eval_results YAML on the model's main branch and in open PRs, and compares by dataset and task rather than by filename.
- If a score is already there it is marked
already_present. - If a different score is there it is flagged as a
score_conflict. - If the model repo doesn't resolve on the Hub it is marked
missing_hf_model. - Everything else is marked
ready.
Nothing gets pushed without your sign-off. The tool writes local YAML previews and a review file you can inspect, shows a report of what is ready and what needs attention, and only opens PRs after you type OPEN PRS and enter a commit message. Reruns reuse the cached results for a collection unless you pass --force.
Start here
Submit your full records to the EEE datastore. If you already contribute to EEE this is one extra step, and the converter handles most of it.
-
The GitHub repo has the community eval converter tool. Run it on a collection:
uv run tools/hf-community-evals/community_evals_converter.py MMLU-Pro \ --datastore evaleval/EEE_datastore@main -
Review the previews and the report it generates.
-
Type
OPEN PRSwhen you're ready to submit.
Full documentation for the schema, CLI, and converters is at evalevalai.com/every_eval_ever/hf-community-evals.
Adapted from "Cross-post your Every Eval Ever results onto Hugging Face model pages," by Nelaturu Sree Harsha, Nathan Habib, and Avijit Ghosh.