Evaluation Cards: A Guide for Everyone
Plain-language: what an AI "benchmark score" really means, and how to read these cards.
You don't need a technical background for this guide. If you've seen headlines like "New AI model scores 90% on a reasoning test!" and wondered what that actually means, you're in the right place.
What is this website?
Evaluation Cards is like a nutrition label for AI model test results.
When companies build AI models, they run them through standardized tests called benchmarks (think: a standardized exam for AI). They then publish scores. But a score by itself, "92%", leaves out a lot: Who gave the test? Under what conditions? Can anyone else get the same result? Were important topics even tested?
Evaluation Cards collects these scores from across the industry and also shows you what's missing, so a polished number doesn't get mistaken for the full story.
Why a single score can be misleading
Imagine a student says "I got 95% on the exam." Reasonable follow-ups:
- Which exam? (An easy one or a hard one?)
- Did they grade it themselves, or did an independent teacher?
- Could someone else re-take it under the same conditions and get a similar result?
- Did the exam even cover the topics you care about?
These are exactly the questions Evaluation Cards helps you ask about AI models. A high score with no answers to these questions is just a number.
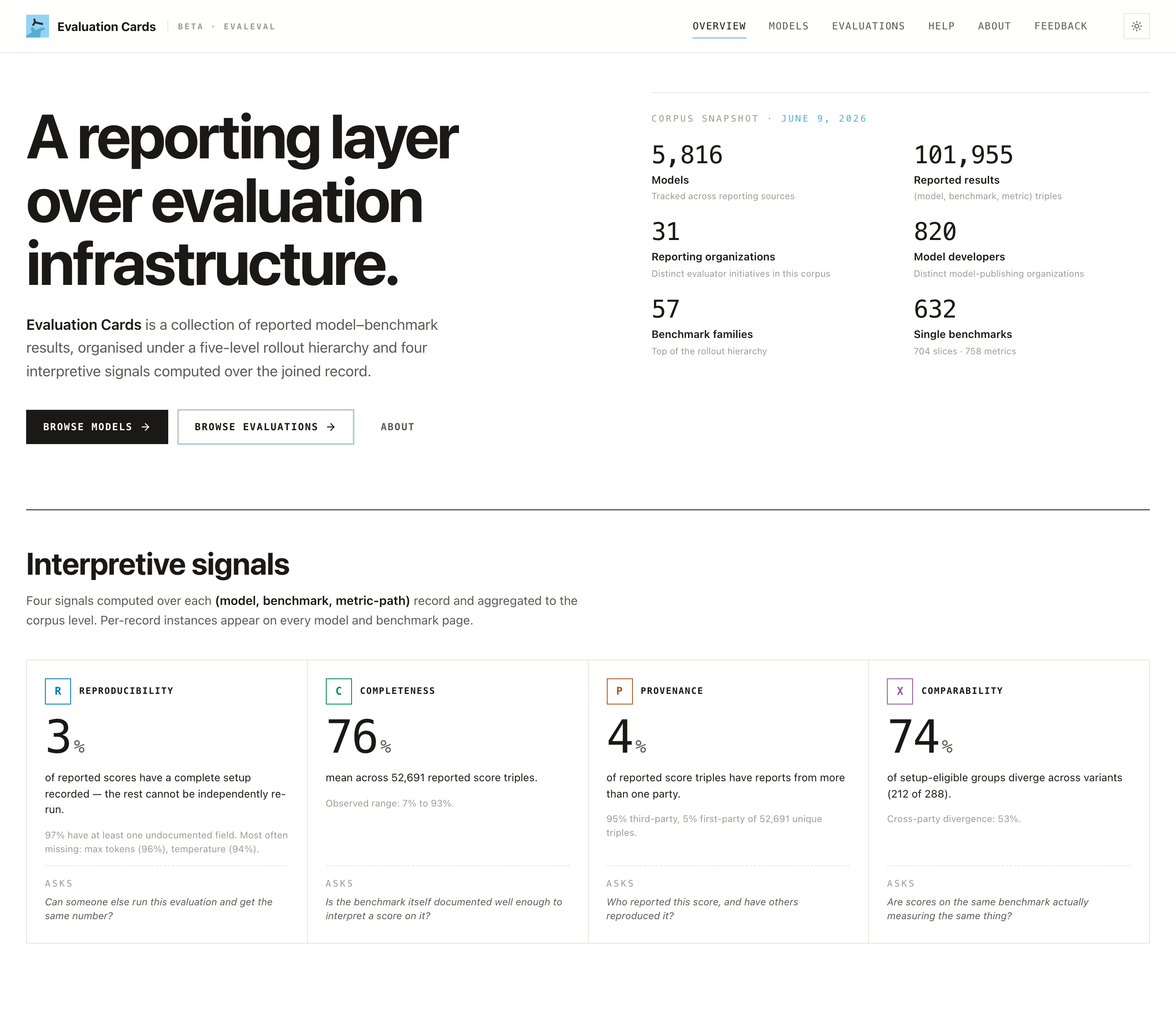
The four things to check (the "signals")
Every result is rated on four simple ideas. You don't need the math, just the gist.
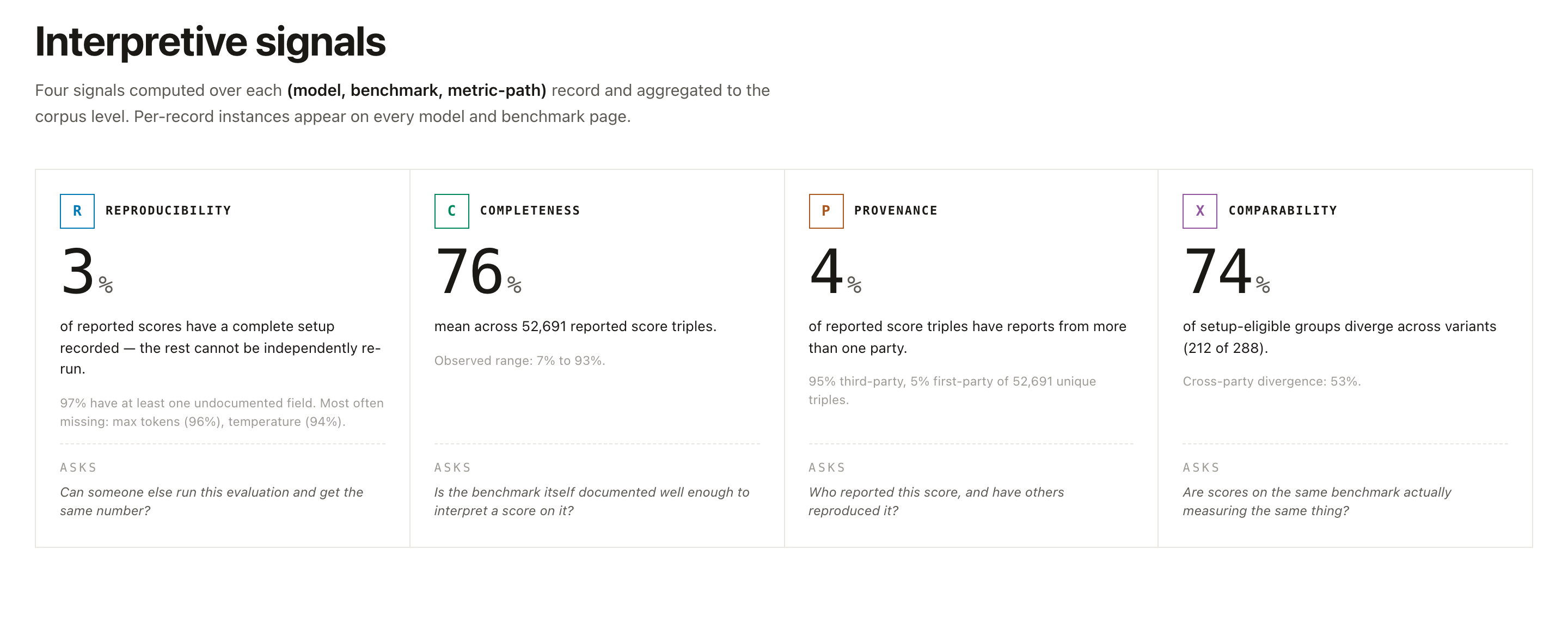
| Signal | In plain words |
|---|---|
| 🔁 Reproducibility | Could someone else repeat this test and get the same result? If the details are secret, the answer is "we can't tell." |
| 📋 Completeness | Did they test the things that matter, not just the flattering stuff but also safety and fairness? |
| 👤 Provenance | Who ran the test: the company that made the model, or an independent group? |
| ⚖️ Comparability | Can you fairly compare this model's score to another model's? (Sometimes it's apples vs. oranges.) |
The big one for everyday readers: Provenance. A company grading its own homework isn't wrong, but it isn't the same as an independent referee. The site always shows you which is which.
How to read a model's page
Let's walk through one.
Step 1: Find a model. Click Models in the menu and pick one you've heard of.
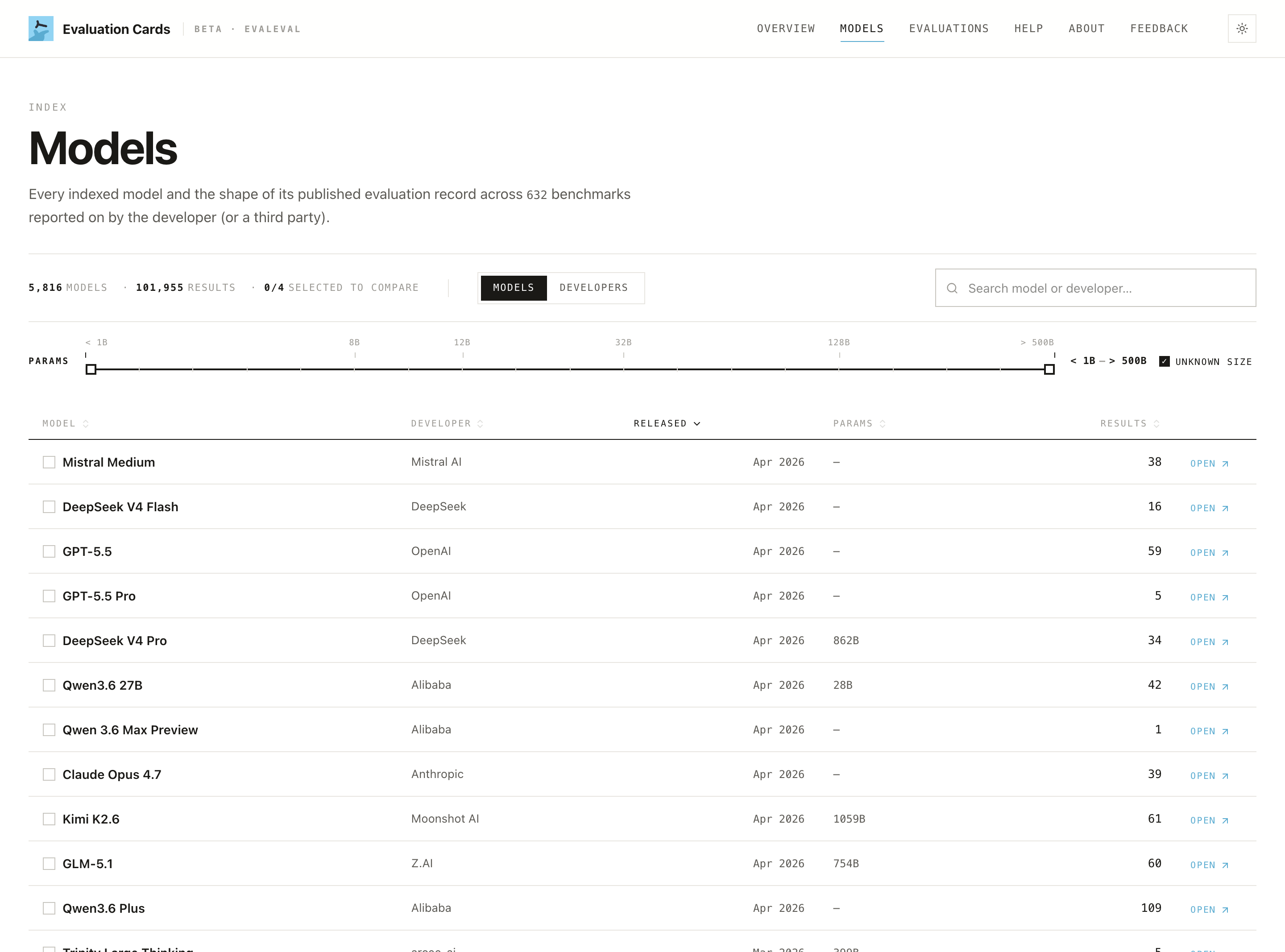
Step 2: Open its page. Each model has its own page.
Step 3: Look for the "Documented" number. Near the top you'll see something like "36% documented." Higher means more of the test details were shared. A low number isn't a scandal; it's just telling you "take these scores with a grain of salt; a lot wasn't disclosed."
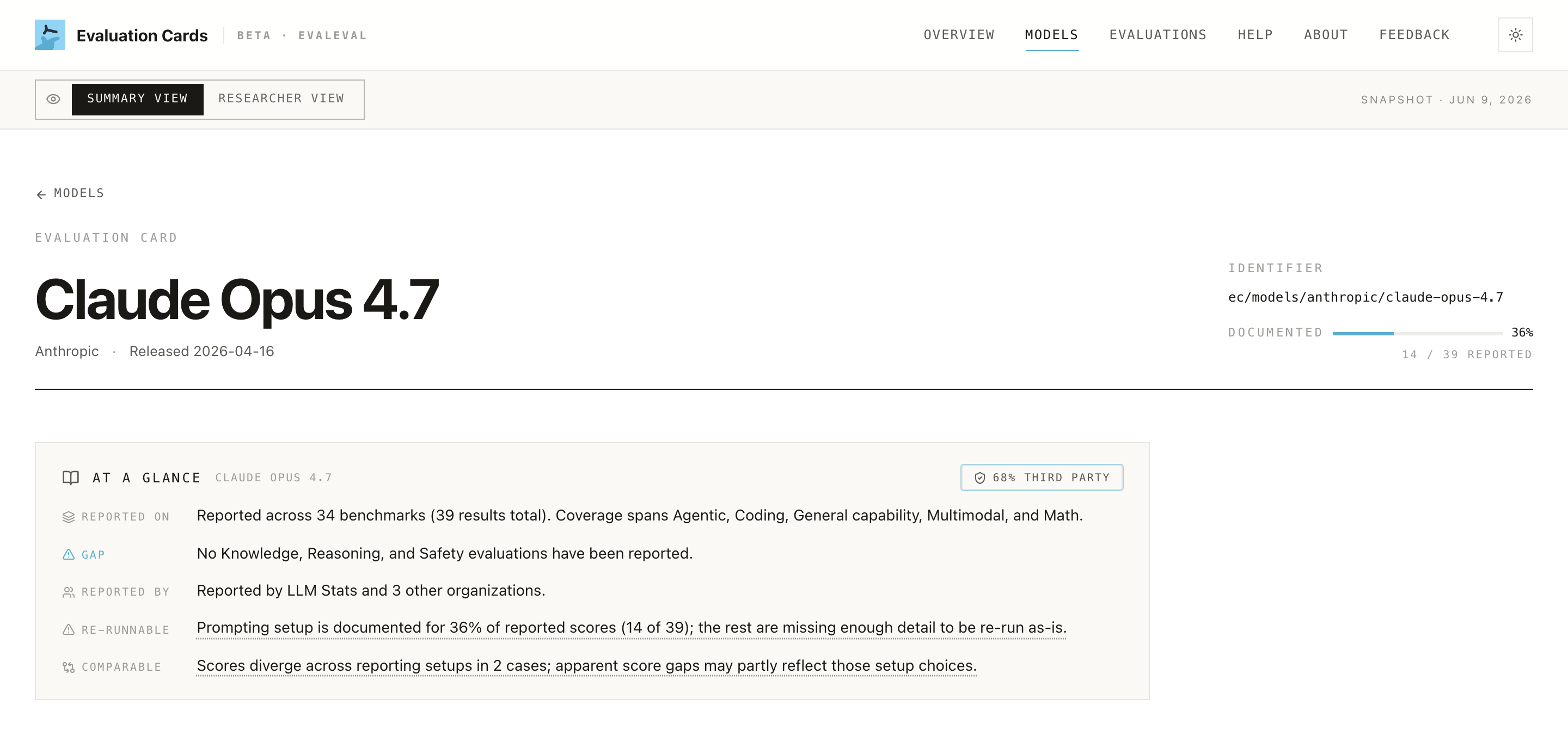
Step 4: See who did the testing. Scroll to "Who reports what." A simple chart splits results into the company's own results vs independent ones.
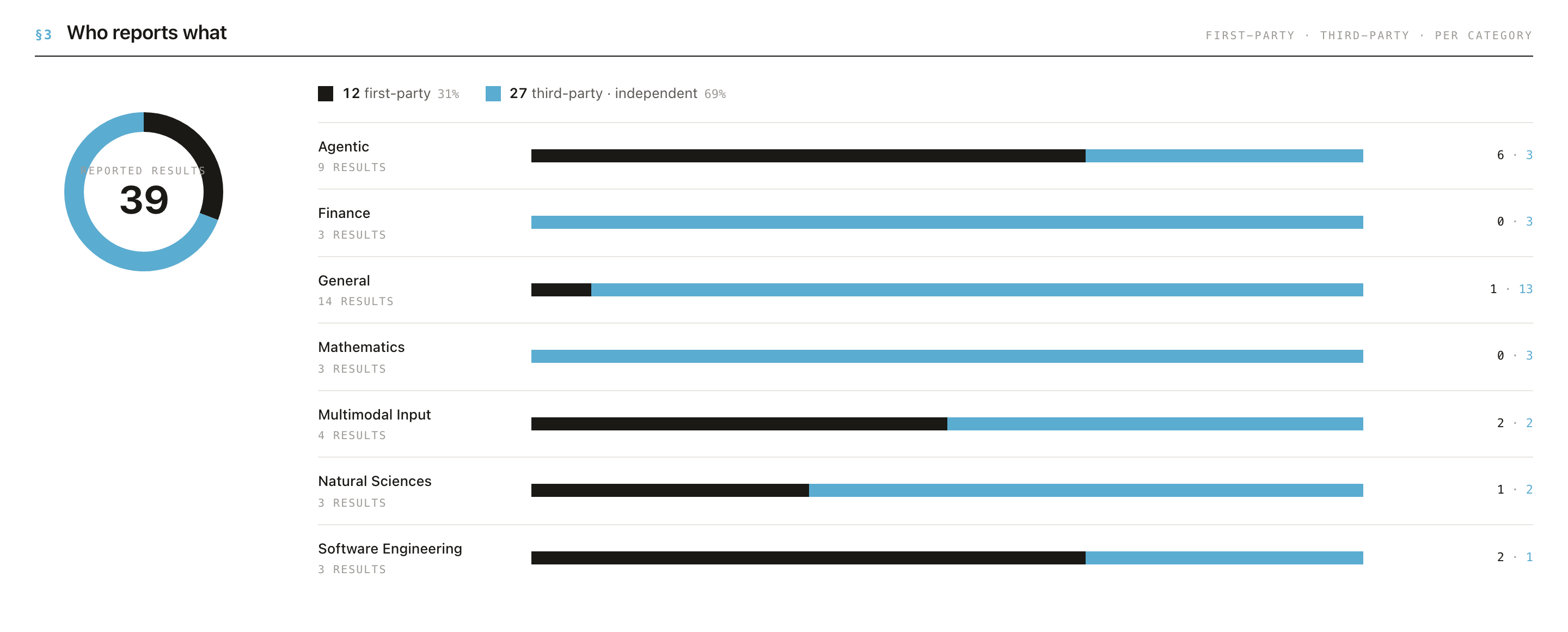
That's it. You can stop there and already read these results more wisely than most headlines do.
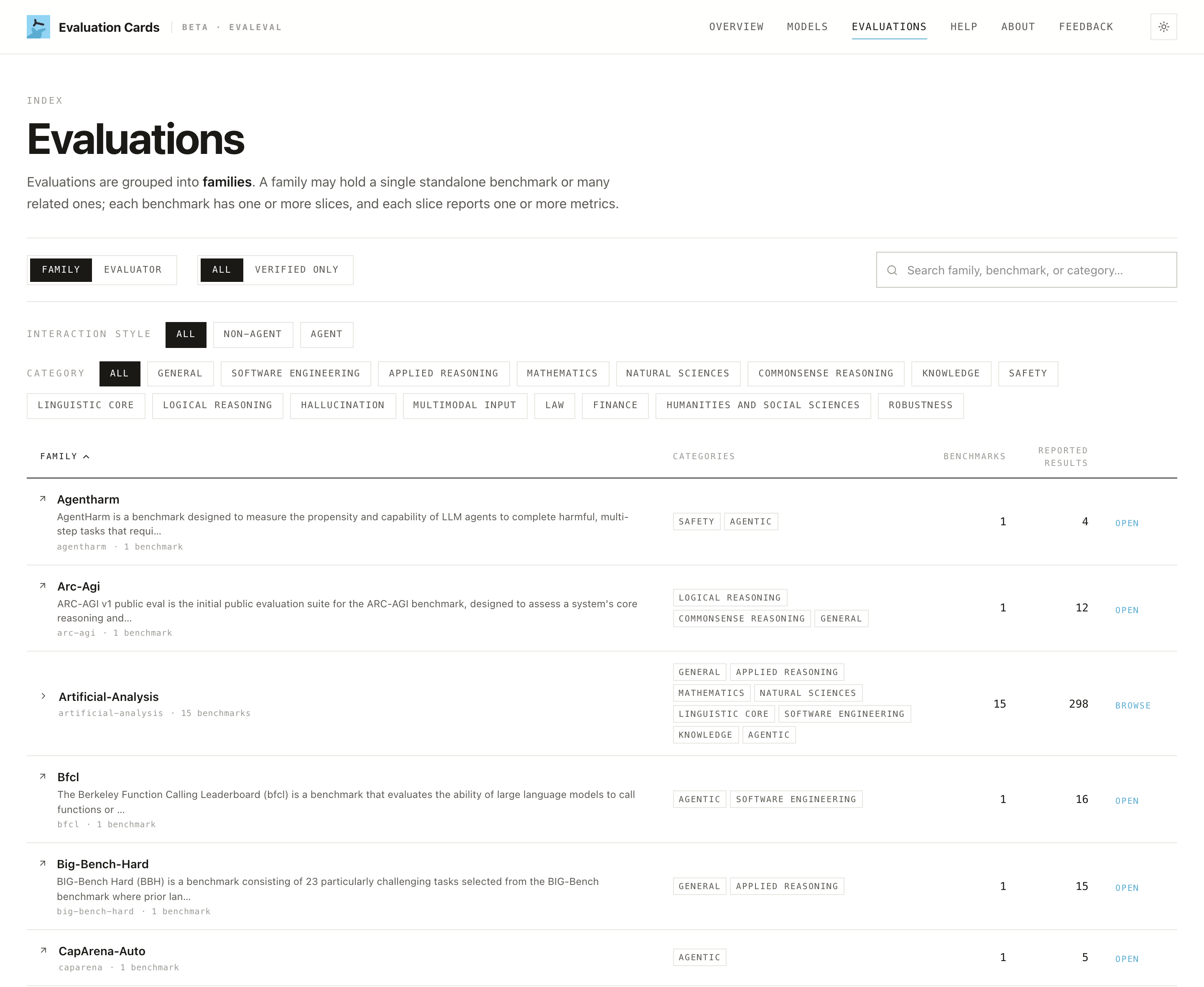
Looking up a test (benchmark)
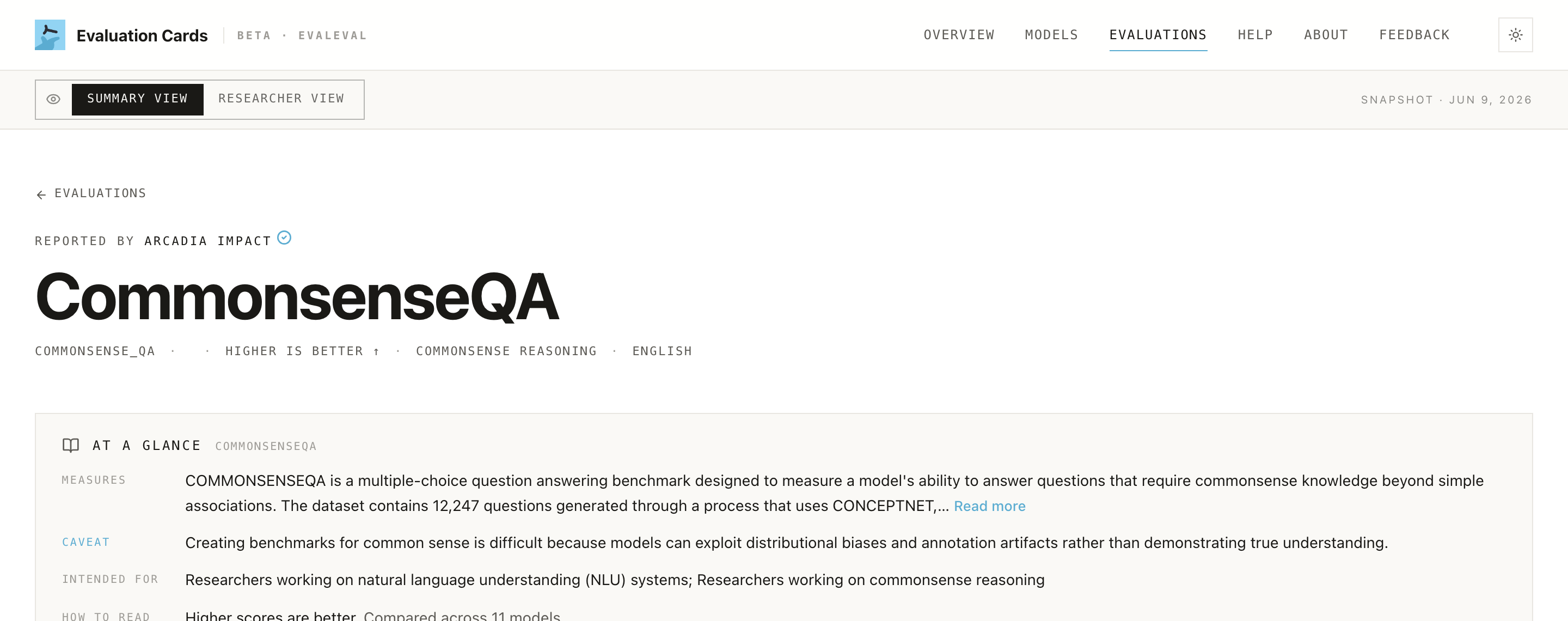
The Evaluations tab lists the tests (benchmarks) that models are scored on. Open one and the At a glance box explains, in plain terms, what the test checks, its main catch, and who it's for, so a name like "MMLU" stops being a mystery.
What this site is not
- ❌ It's not a "best AI" leaderboard. It won't crown a winner.
- ❌ It won't tell you a model is "safe," only how thoroughly (and by whom) it was tested.
- ❌ Blanks are not zeros. A blank means "nobody reported this," not "the model failed."
Three takeaways
- A score is a claim, not a guarantee. Always ask who measured it and how.
- Independent results carry more weight than a company testing its own product.
- What's missing matters. If safety was never tested, the absence is part of the story.
That's the whole idea: not "which AI is best," but "how much should we trust what we're being told about it?"
➡️ Curious for more? The Quickstart goes a little deeper without getting technical.