Evaluation Cards for Evaluation Researchers
How to use Evaluation Cards as a working tool for studying, auditing, and comparing model evaluations.
Prerequisite: skim the Quickstart first for the four signals and the five-level hierarchy.
Why this matters for your work
If you study evaluations, you already know the core problem: published benchmark numbers are rarely accompanied by the prompts, decoding settings, harness versions, seeds, or evaluator identity needed to interpret or reproduce them. Evaluation Cards canonicalizes heterogeneous reporting into a single structured corpus where the absence of those details is recorded explicitly rather than silently dropped.
The design principles that matter most for research use:
- Every score is attributed to its source document. Provenance is first-class.
- Missing values are never imputed. A blank is "not reported," never a guessed number.
- Evaluator identity is preserved. First-party and third-party results are kept distinct.
- Snapshot discipline. No retroactive edits; corrections are versioned. Your analyses are reproducible against a dated snapshot.
Some of our next steps are aimed squarely at research use, including making all evaluation data, metadata plus run-level results, downloadable directly from Evaluation Cards. In the meantime, run-level data is available from Every Eval Ever, the structured datastore that powers the corpus. If there's a feature that would help your work, tell us on the public roadmap. We'd love to build what the research community needs, so let us know.
The Researcher View
The model page has two modes, toggled top-right. Use Summary View to get oriented, and Researcher View to do the actual work.
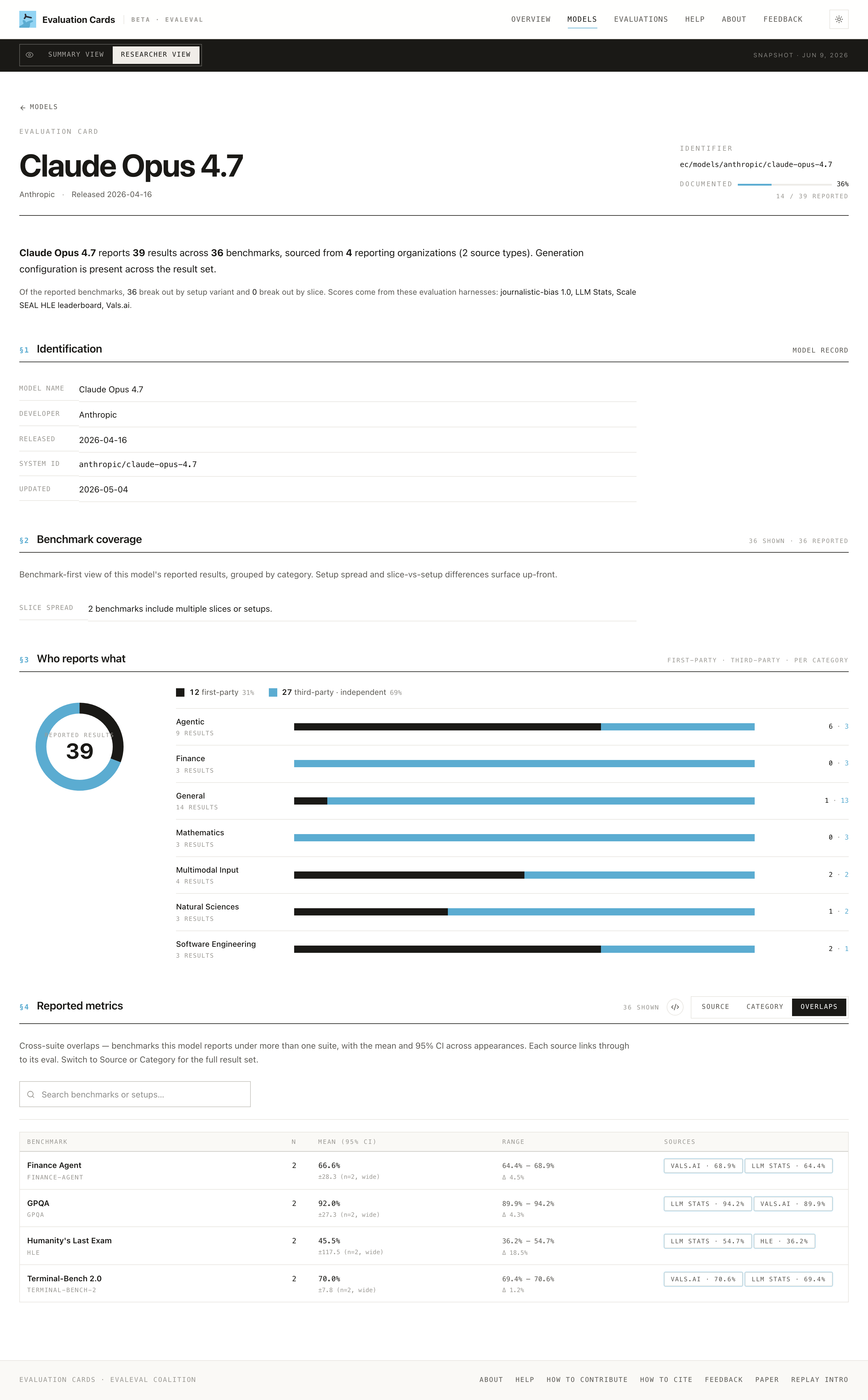
Researcher View exposes the per-result granularity behind the summary aggregates: setup variants, splits, metric paths, source harnesses, and the document each number came from.
Working through the page, section by section
A model page is organized into four numbered sections.
§1 Identification
Model name, developer, release date, modalities (e.g. image, text → text), system ID, and last-updated. The stable identifier (ec/models/<dev>/<model>) is what you cite.

§2 Benchmark coverage
A benchmark-first view grouped by category, surfacing setup spread and split-vs-setup differences up front. Watch the "split spread" note (e.g. "2 benchmarks include multiple splits or setups"). These are exactly the cases where naïve aggregation hides variance.

§3 Who reports what
A first-party / third-party split as a donut plus per-category bars. This is the provenance signal made concrete. In the captured example (Claude Opus 4.7, 39 results): 12 first-party (31%) vs 27 third-party (69%), with per-category breakdowns (e.g. Finance: 0 first-party · 3 third-party; Multimodal Input: 2 · 2).
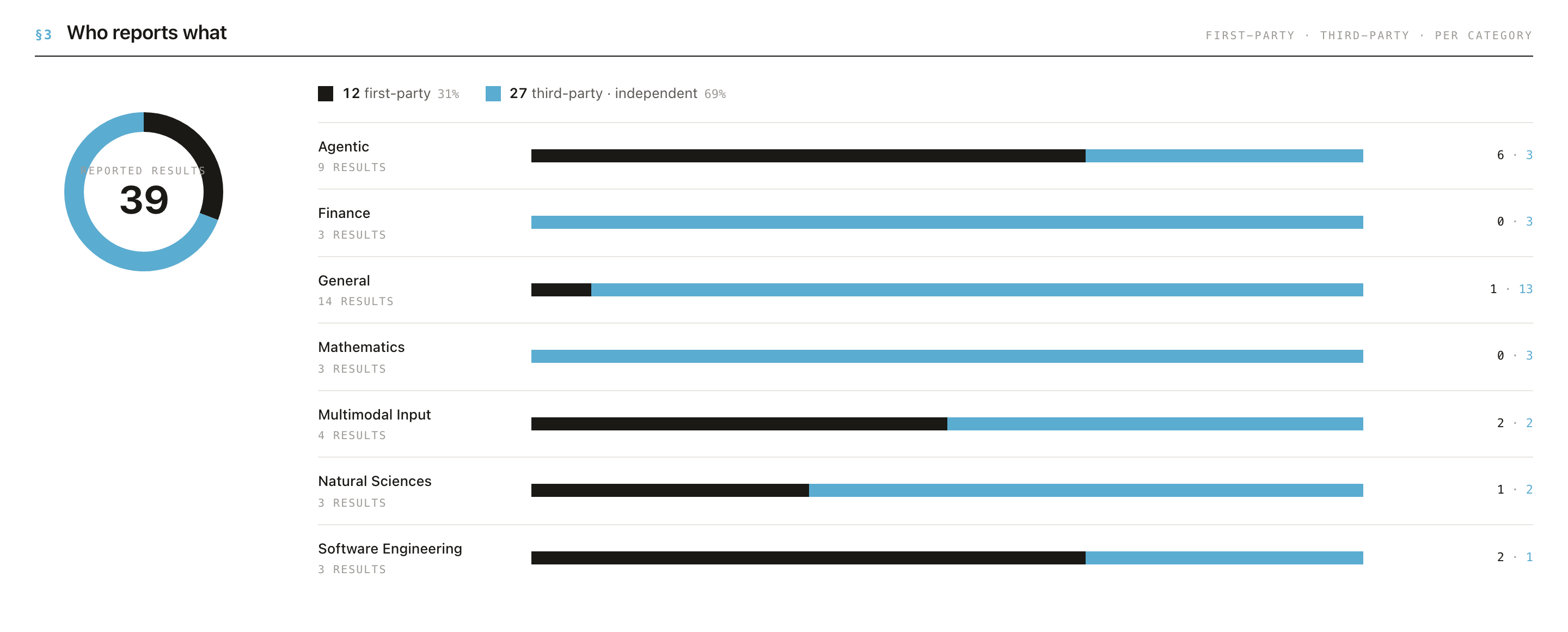
For research: a category that is entirely first-party is a known blind spot: there is no independent corroboration of those numbers.
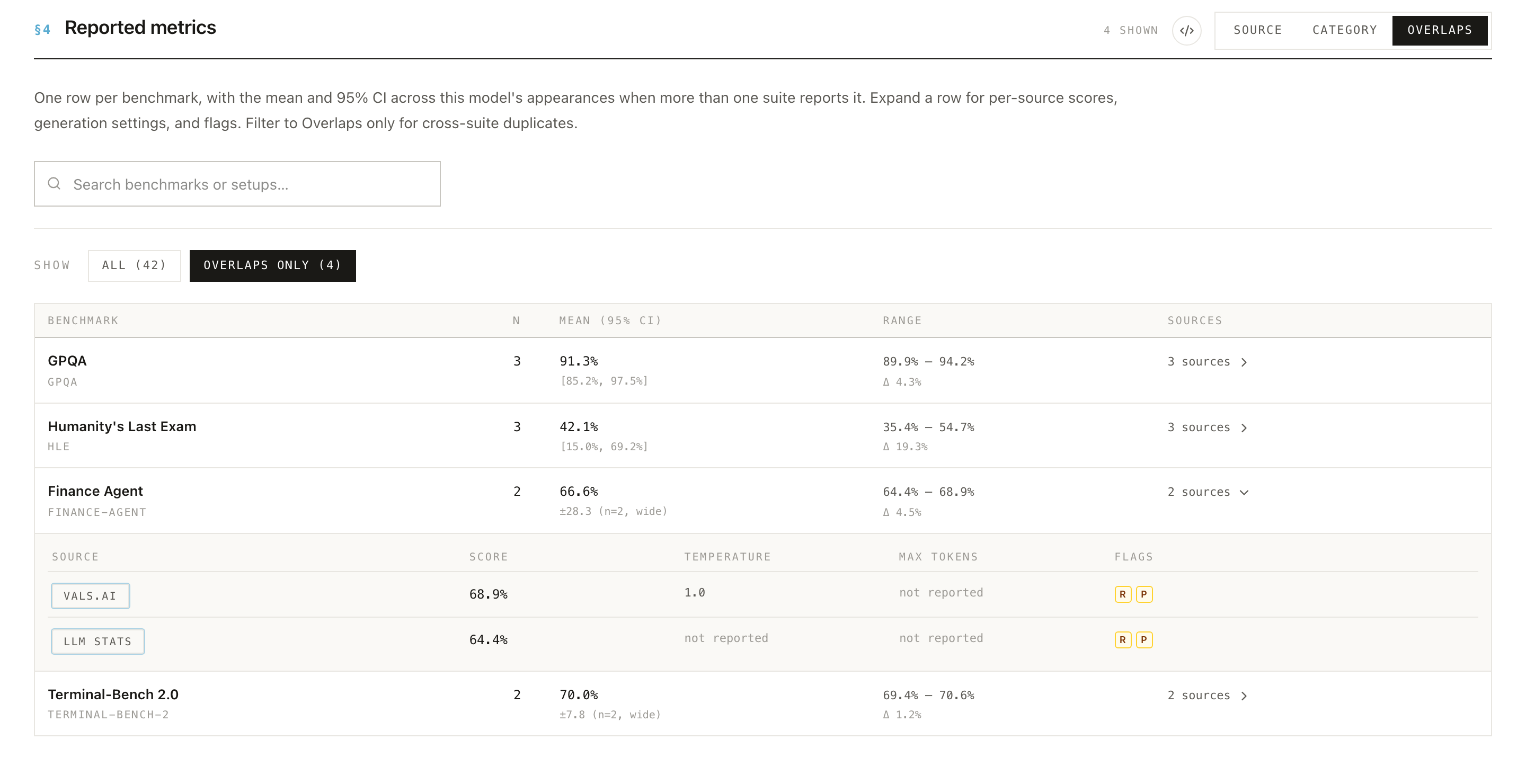
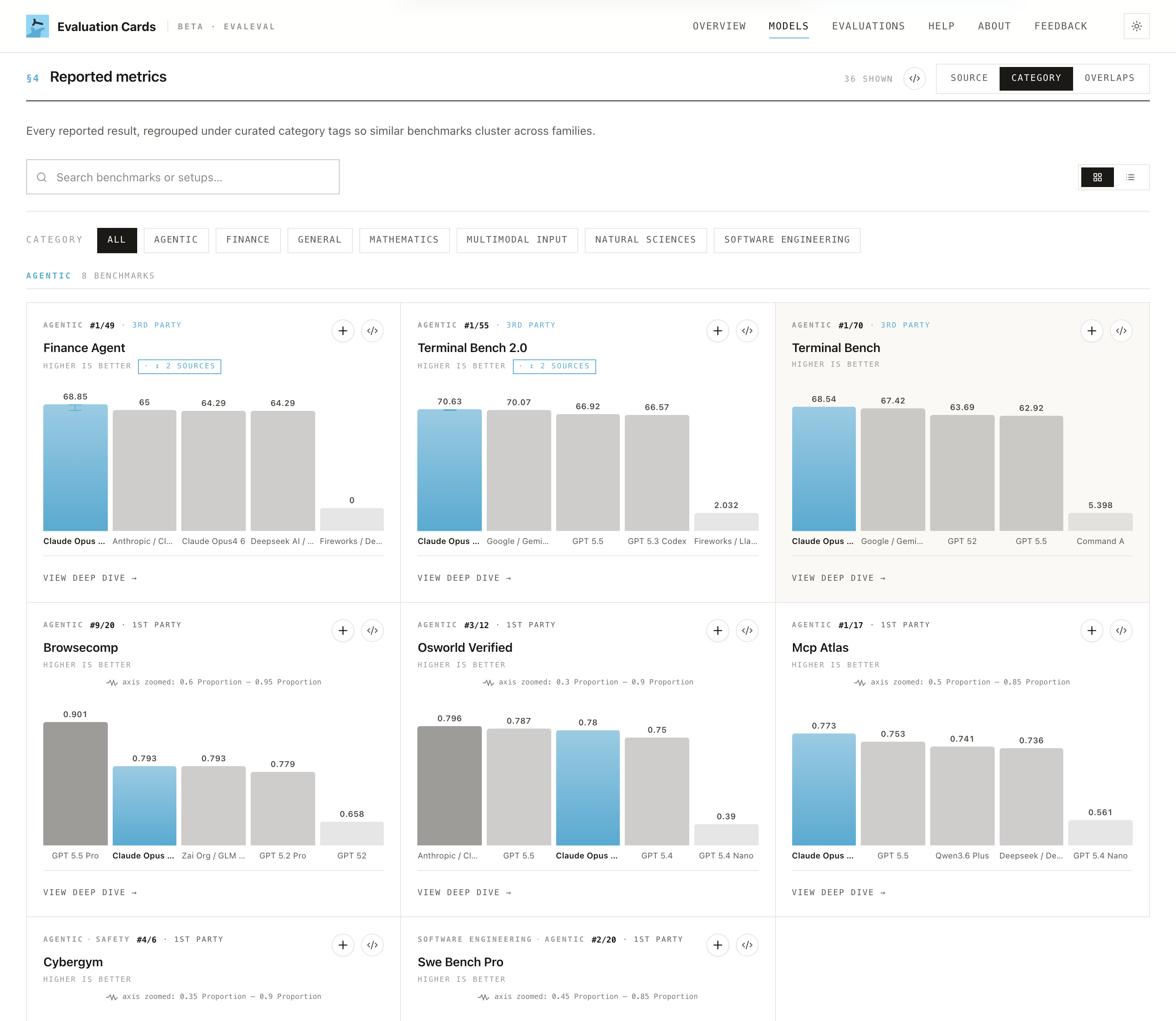
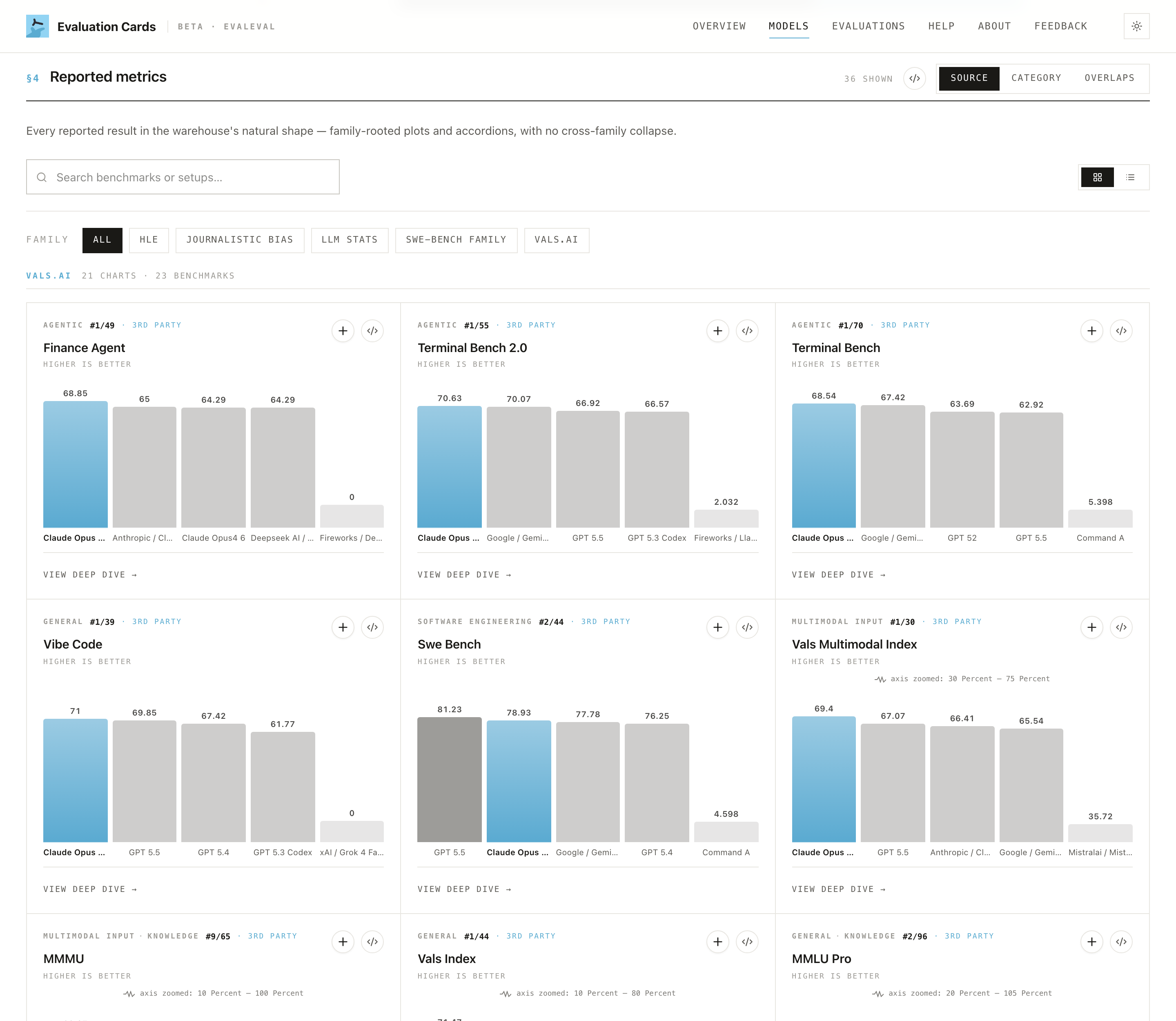
§4 Reported metrics
This is where you read off the actual numbers. In Researcher View the section has a grouping toggle for Overlaps, Category, and Source, plus a family selector, a search box, and a grid/list switch. Each grouping answers a different question.
Overlaps gives one row per benchmark, with the mean and 95% CI across this model's appearances and the range of reported scores (plus a Δ for how far the numbers move). Expand any row to see each source's score, its generation settings, and the per-result flags for the signals that result trips. The All / Overlaps only filter narrows the list to benchmarks reported by more than one source, where divergence is easiest to spot.
Category regroups every reported result under curated category tags, so similar benchmarks cluster across families. Read the model's profile by capability area (math, safety, agentic, …) rather than by benchmark name.
Source is the warehouse's natural shape: family-rooted plots and accordions with no cross-family collapse. This is the full result set; drill into any plot for the per-result setup context. (The section opens in Overlaps when a model has any; switch here for everything.)
Reading the four signals rigorously
| Signal | What to inspect | Research caution |
|---|---|---|
| Reproducibility | Disclosure of setup variants, prompts, decoding params, harness version, seeds, code availability. | "Reproducible in principle" ≠ "reproduced." Only ~3% of scores have complete setup documentation corpus-wide. |
| Completeness | Coverage across capability / robustness / safety / fairness for the model class. | A complete capability record can still be silent on safety. Completeness is relative to expectations, not absolute. |
| Provenance & Risk | First- vs third-party; mapping to IBM Risk Atlas risk domains. | First-party numbers are not wrong, but they are not independent. Check §3 before ranking. |
| Comparability | Split, metric variant, and unit differences within the same benchmark. | Two "MMLU" numbers may use different splits or metrics, flagged here. Do not rank across incomparable setups. |
Comparing models and benchmarks
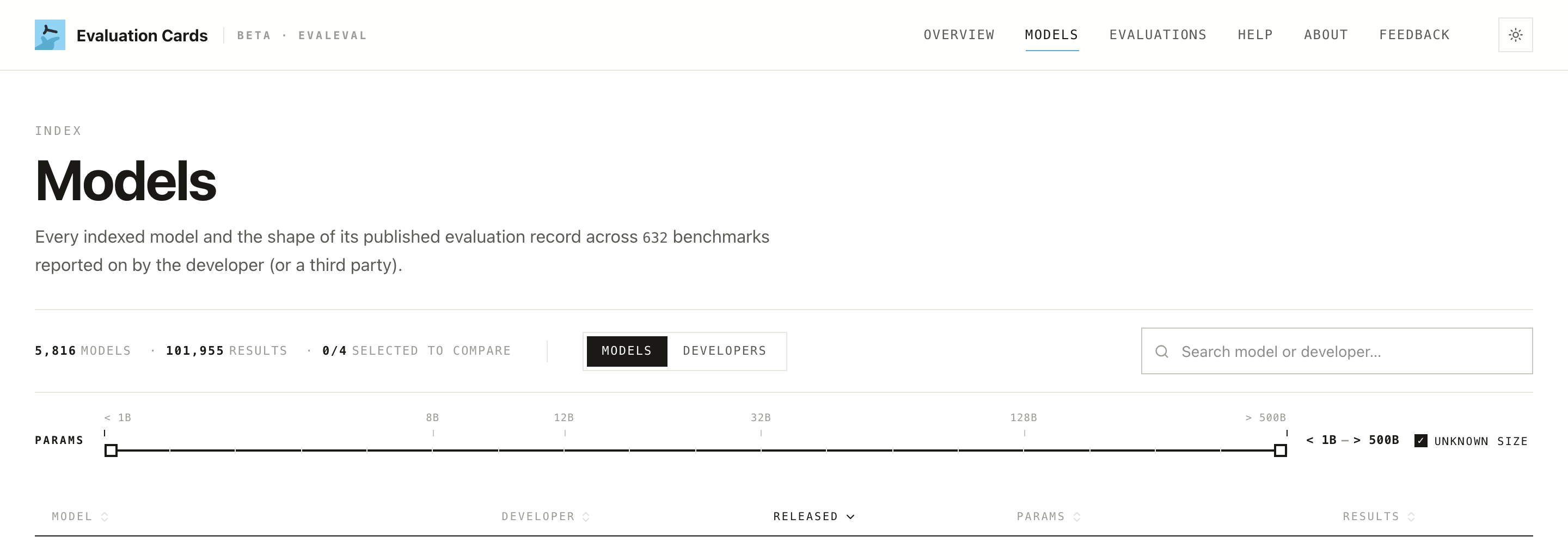
- Models index (
/models): filter by parameter range (< 1B…> 500B, presets at 8B/12B/32B/128B, plus an Unknown size option), and toggle Models ↔ Developers.
-
Side-by-side compare: select up to four models via the Add to compare buttons.
⚠️ As of this writing the populated compare view is intermittently unavailable on the beta backend (cold-start errors). If it fails, retry after a few seconds.
-
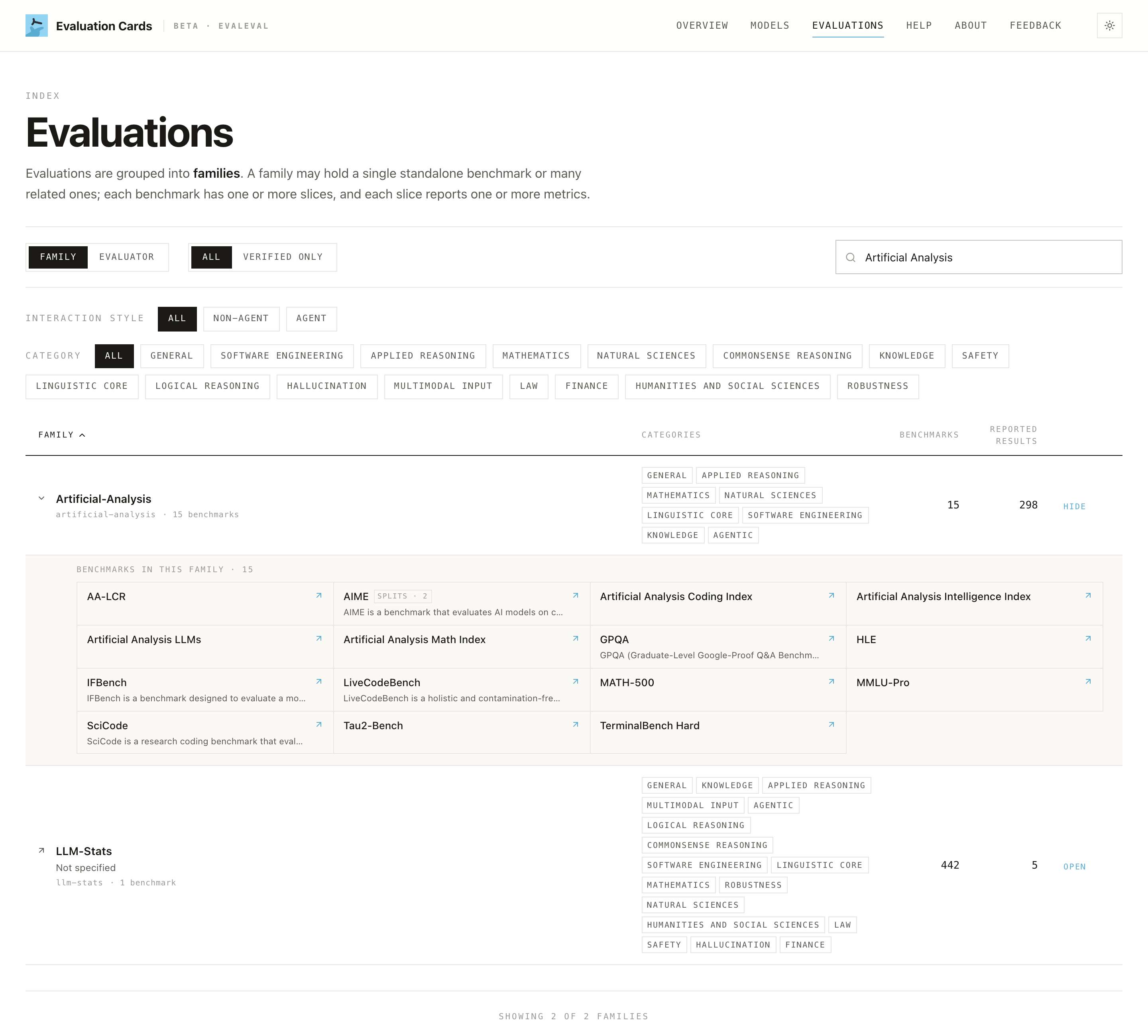
Evaluations index (
/evals): families filterable by interaction style (agent / non-agent) and category. Drill into a family at/evals?family=<slug>to see its benchmarks → splits → metrics.
Limitations
- Comparability is bounded by setup. The site flags when two scores under the same benchmark are not directly comparable, so respect those flags in any ranking or meta-analysis.
- Coverage ≠ quality. Many results with weak documentation can look like "good coverage." Weight by the signals.
- The corpus reflects what was reported, not all that exists. Undisclosed evaluations are absent by definition.
- Pin a snapshot. Cite
ec/models/...identifiers plus the snapshot date so your analysis is reproducible.
➡️ Related: Policymakers (governance framing) · Quickstart.