Evaluation Cards for Policymakers
How to read AI evaluation evidence for governance decisions: what it supports and what it does not.
Prerequisite: the Quickstart explains the four signals and the snapshot model in a few minutes.
The one idea to take away
When a company says "our model scored X% on a safety benchmark," that is a claim, not an audited fact. Evaluation Cards exists to show you the quality of the evidence behind such claims: who produced it, whether it can be reproduced, and whether it can be fairly compared to anyone else's number.
For policy, the headline score is rarely the variable that matters. The documentation and independence behind it usually are.
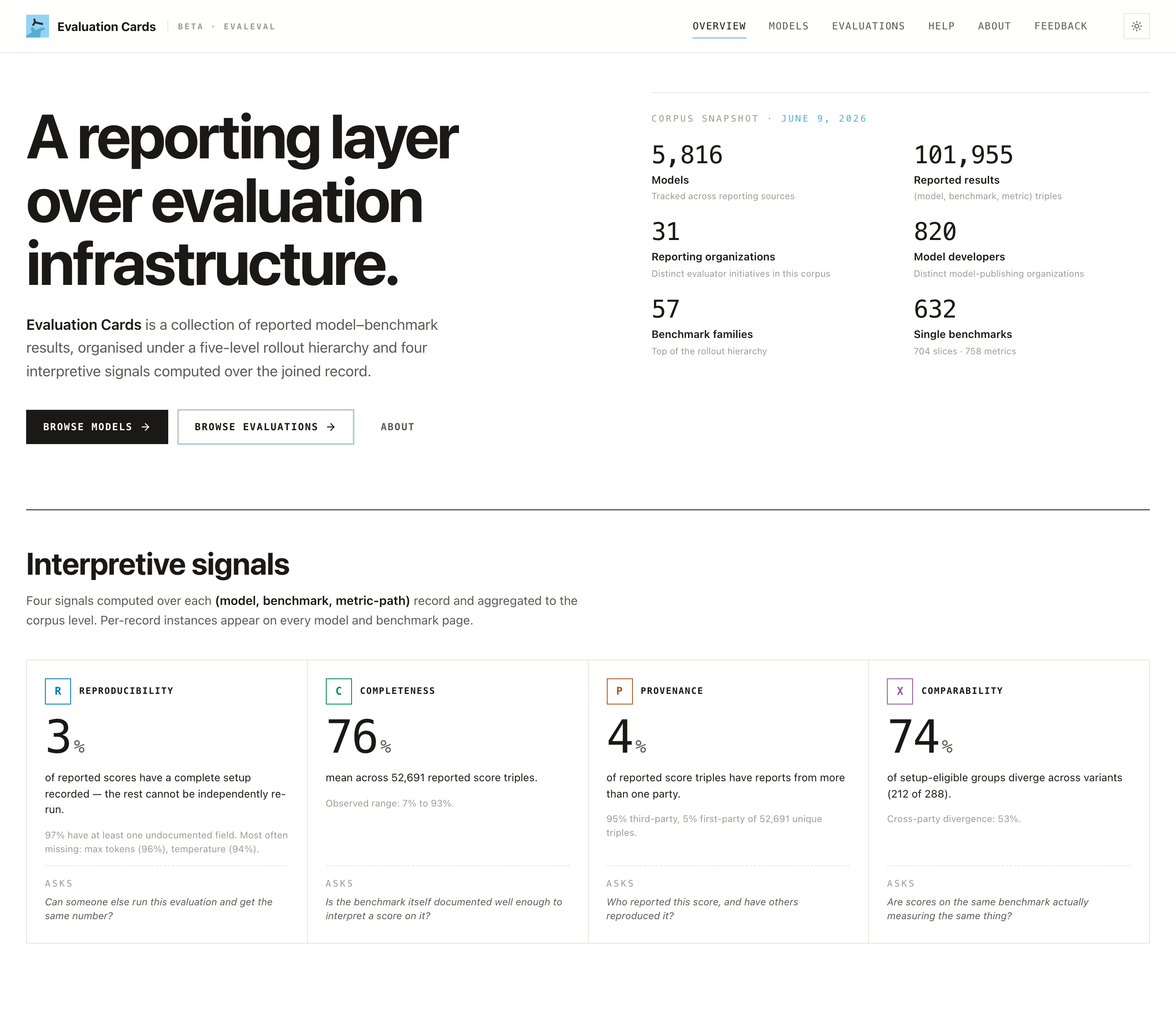
What the corpus does and does not tell you
It does:
- Aggregate how thousands of models have been evaluated, across many independent reporting organizations.
- Make explicit what was not disclosed, treating undocumented setups as a measurable gap, not an oversight.
- Distinguish a developer's own results from independent third-party evaluations.
It does not:
- Certify that any model is "safe," "compliant," or "best." There is no ranking or seal of approval.
- Fill in missing data. A blank means "not reported," never an estimate.
- Replace an audit. It tells you how auditable a claim currently is.
Reading the four signals as a governance lens

| Signal | Governance question | Why it matters for policy |
|---|---|---|
| Reproducibility | Could an independent party verify this claim? | A score that cannot be reproduced cannot be relied on for oversight. Corpus-wide, only ~3% of scores have complete setup documentation. |
| Completeness | Were the relevant risk areas evaluated at all? | A strong capability record can be silent on safety, robustness, or fairness. Absence of a result is not evidence of safety. |
| Provenance & Risk | Who ran the evaluation, and what real-world risk does it speak to? | Self-reported results lack independent corroboration. Results map to IBM Risk Atlas risk domains, connecting scores to recognized risk categories. |
| Comparability | Can these two models actually be compared on this benchmark? | "Model A beats Model B" is often invalid if they used different setups. The site flags when a comparison is not legitimate. |
First-party vs third-party: the independence check
The single most useful view for governance is §3 "Who reports what" on any model page. It splits a model's results into:
- First-party: produced by the model's own developer.
- Third-party: produced independently.
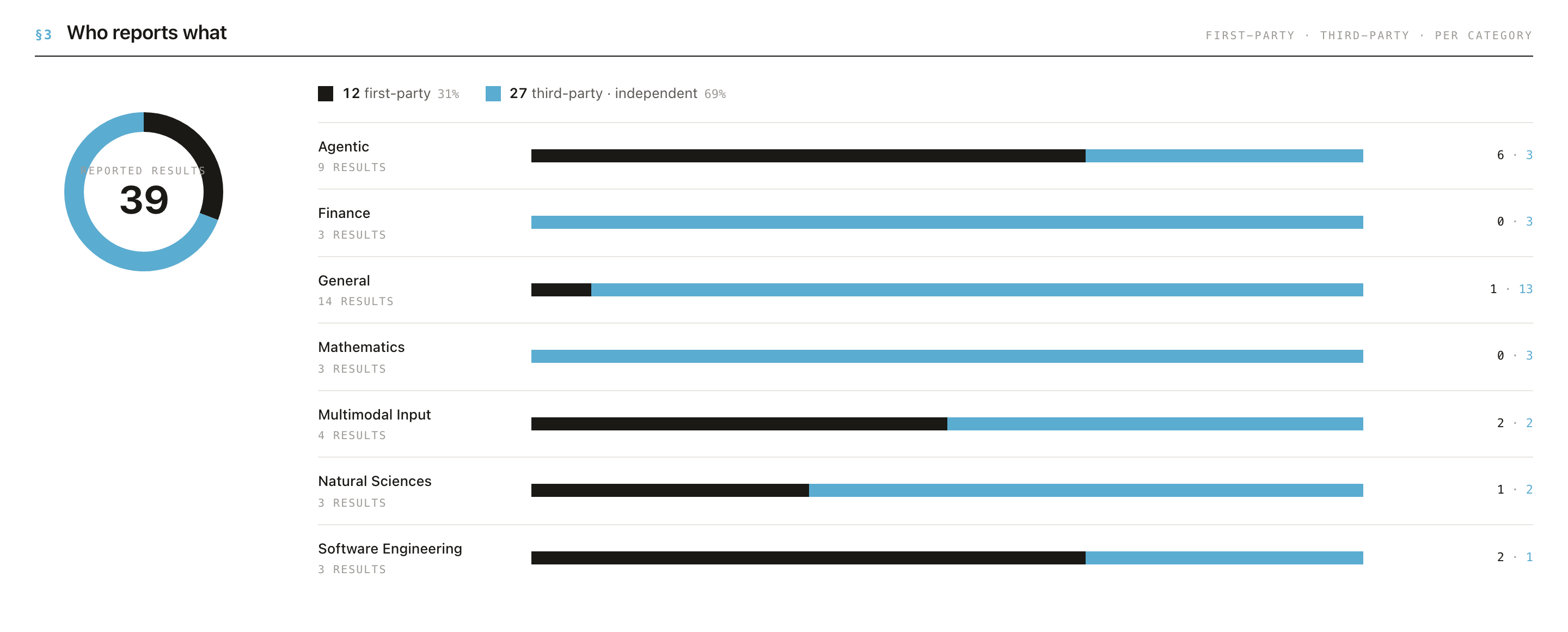
In the captured example, a flagship model's record was 31% first-party / 69% third-party, and some categories were entirely third-party or entirely first-party. A category with no independent evaluations is a place where policy should not lean on the numbers without seeking corroboration.
A short workflow for a policy question
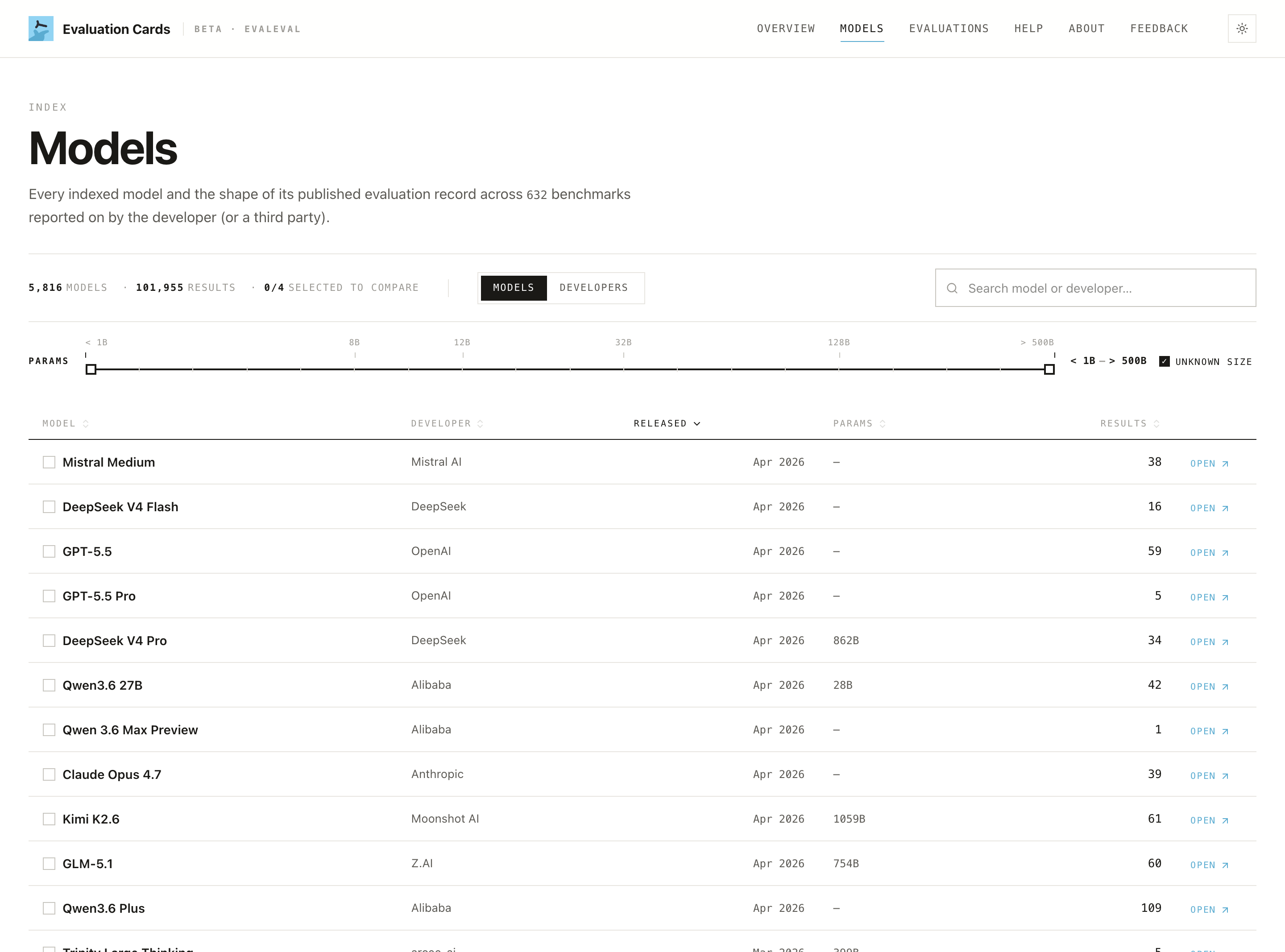
Suppose you need to assess the evidence base for a specific model.
- Open its page. Models → search the model.
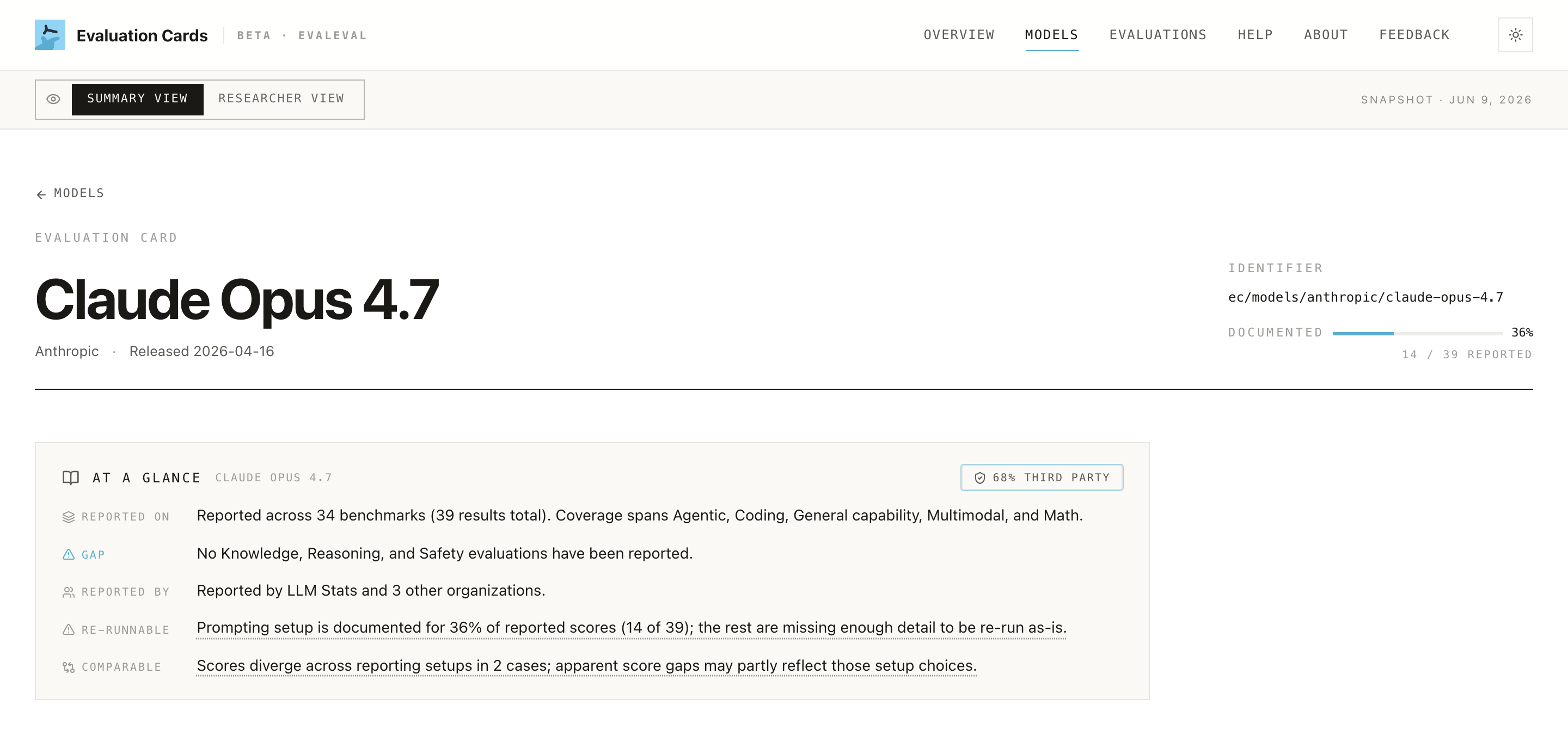
- Read the
DOCUMENTEDbadge (e.g. "36%, 14 / 39 reported"). This is, at a glance, how much of the record is fully documented. Treat a low number as "claims that are hard to verify."
-
Check §3 (Who reports what) for independence, by category.
-
Check §2 (Benchmark coverage) for what risk areas were evaluated at all.

- Note the snapshot date. The corpus is versioned; cite the date.
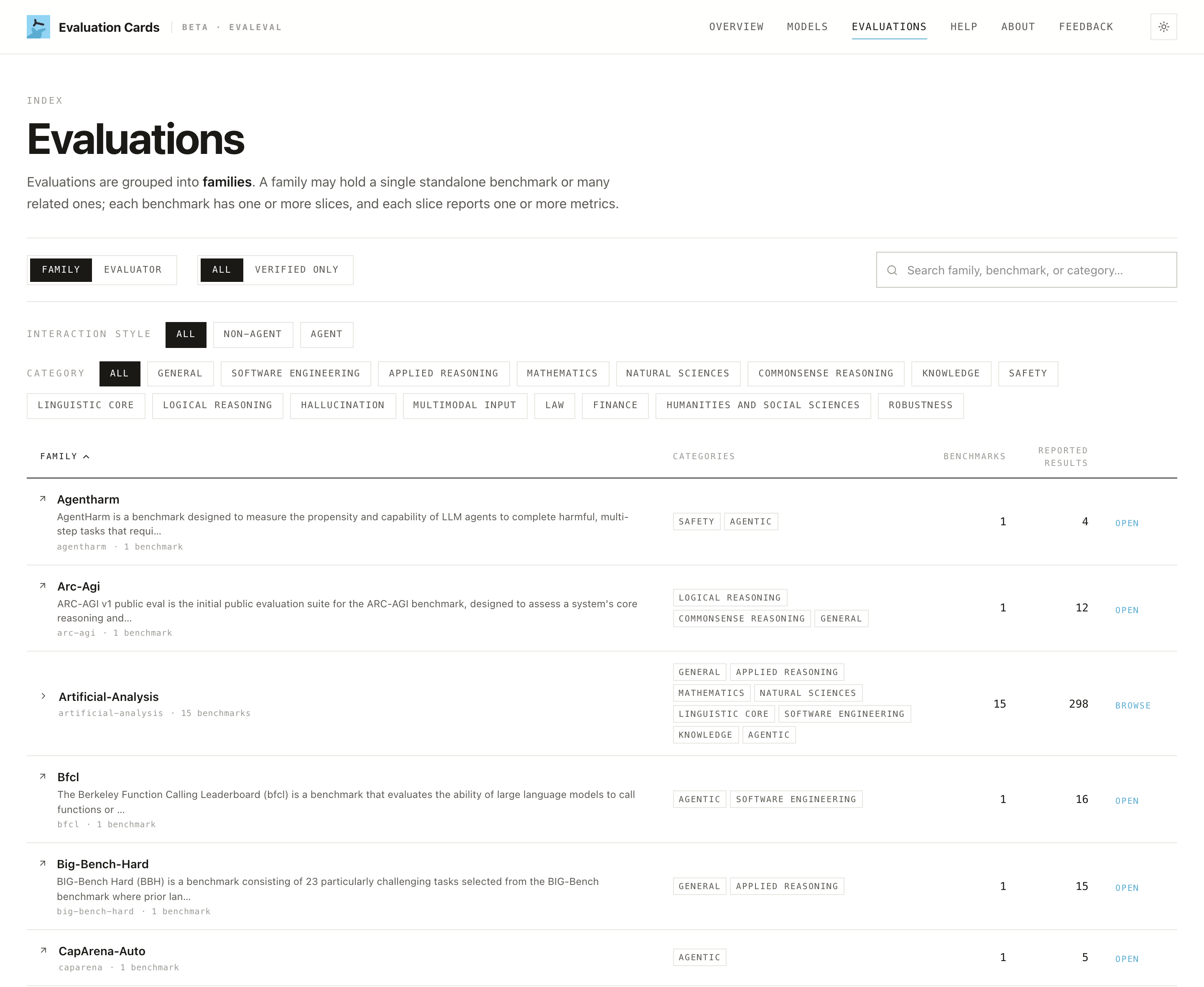
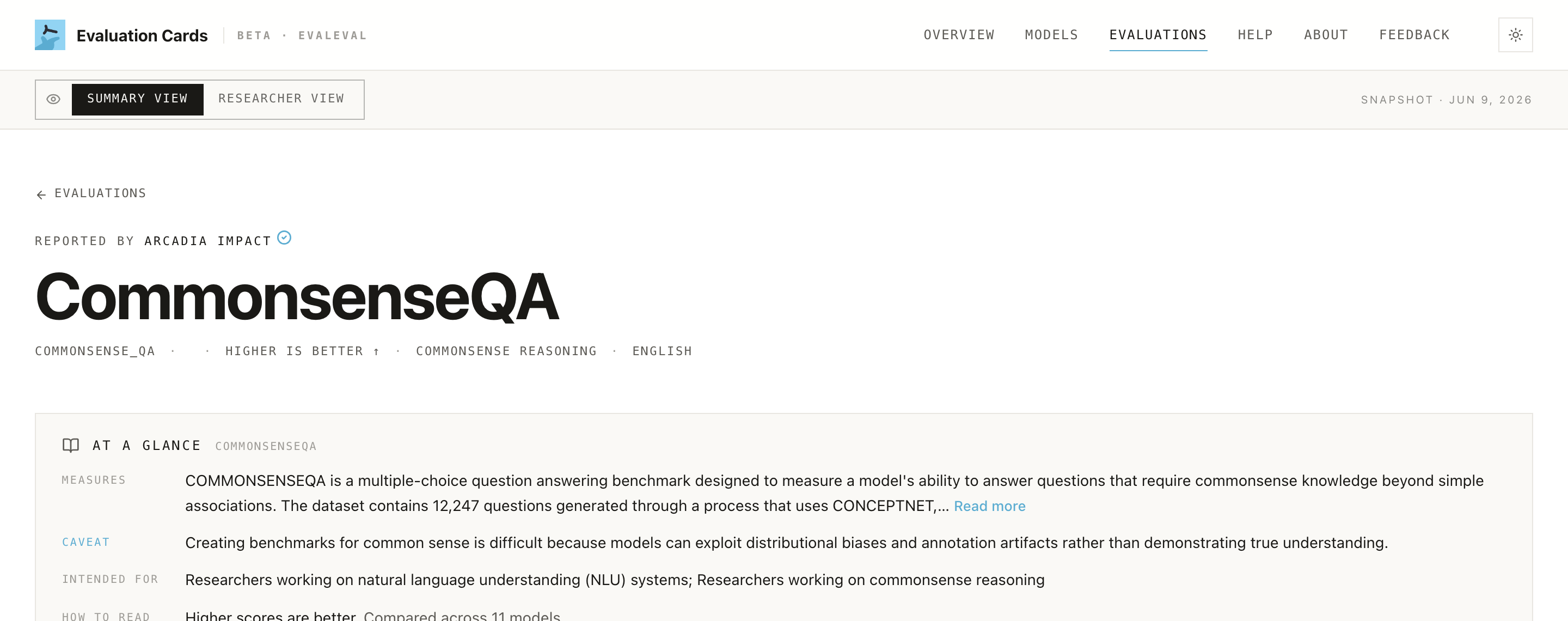
Looking up a benchmark
When a claim cites a specific benchmark ("scores X on a safety benchmark"), the Evaluations tab lets you check what that benchmark actually measures before you weigh the number. Each benchmark's At a glance card states what it tests, its main caveat, and who it's intended for, links to the source, and flags whether scores on it can be compared directly across reporters.
What you can responsibly say
✅ "As of the [snapshot date] corpus, X% of this model's reported results are fully documented, and Y% come from independent evaluators."
✅ "There are no reported [safety / robustness / fairness] evaluations for this model in the corpus." (Absence is itself a finding.)
❌ "This model is the safest" / "This model ranks #1." The corpus does not certify or rank.
❌ Treating a missing value as a low score, or a high score with weak signals as a strong claim.
Why the framing matters
Evaluation Cards deliberately treats an undisclosed detail as a claim intentionally not made, not an error. For policy this is the useful posture: it shifts the question from "what's the number?" to "how much can we trust and verify this number, and who stands behind it?" That is the question governance actually needs answered.
➡️ Related: Journalists (sourcing claims responsibly) · Evaluation researchers (deeper methodology).