Evaluation Cards for Journalists
How to source AI benchmark claims accurately, cite them defensibly, and avoid the common overclaiming traps.
Prerequisite: the Quickstart (~6 min) covers the four signals and the snapshot model.
Why this is a reporting tool, not just a database
AI companies publish benchmark numbers constantly, often in launch posts engineered for headlines. Evaluation Cards lets you do three things fast:
- Verify whether a claimed score is independently corroborated or self-reported.
- Contextualize a number with how well-documented and comparable it actually is.
- Cite a stable, dated source instead of a marketing page.
The project's framing is useful for reporters: a published score is a claim, and an undisclosed detail is a claim deliberately not made. Your job is to report which is which.
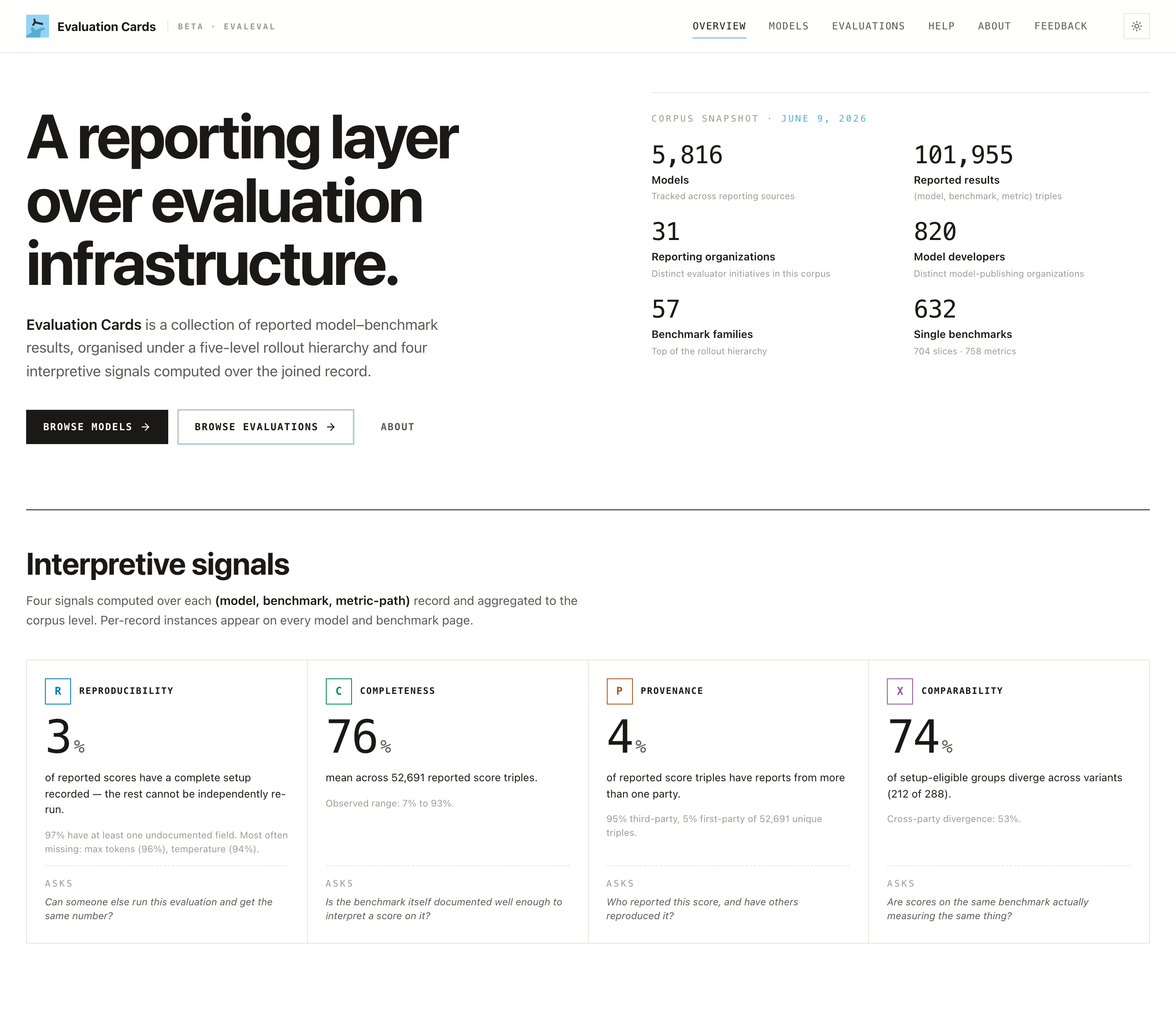
The 3-minute fact-check
A company claims "Model X leads on benchmark Y." Before you repeat it:
1. Find the model page. Models → search.
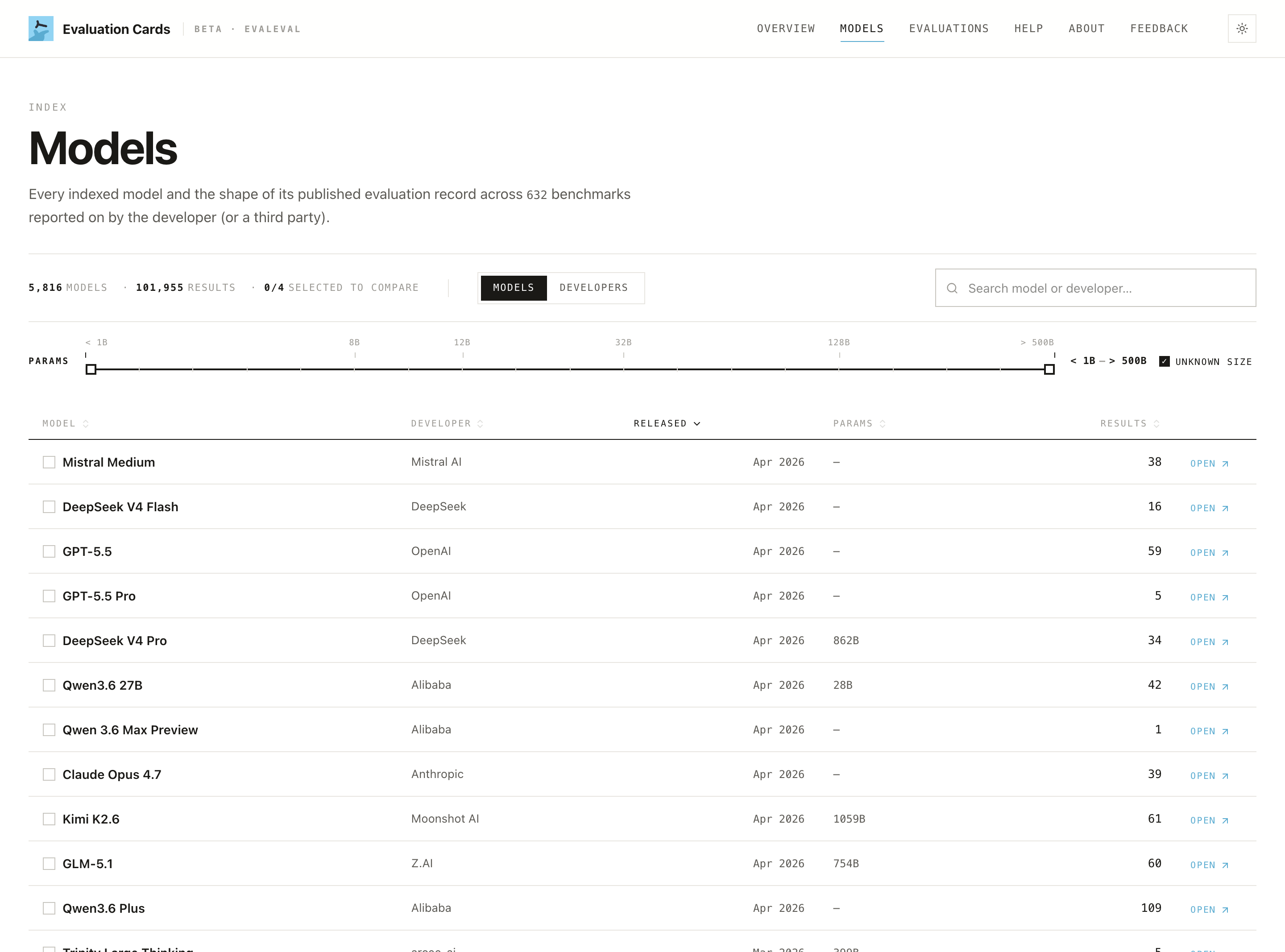
2. Is the claim first-party or third-party? Open §3 "Who reports what." If the impressive number is the company's own result with no independent corroboration, say so in your piece.
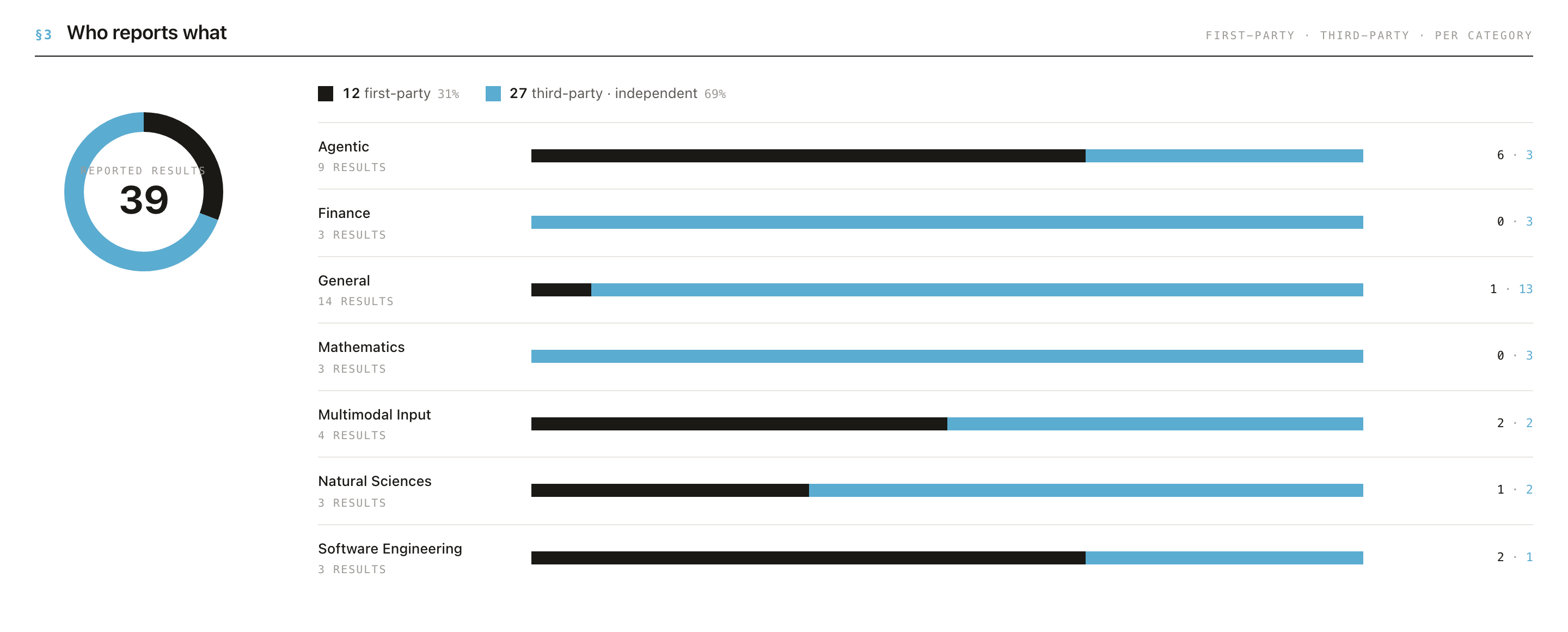
3. How documented is it? The DOCUMENTED badge (e.g. "36%, 14/39 reported") tells you how much of the record is fully specified. A flashy score with weak documentation is a weak claim, worth a caveat.
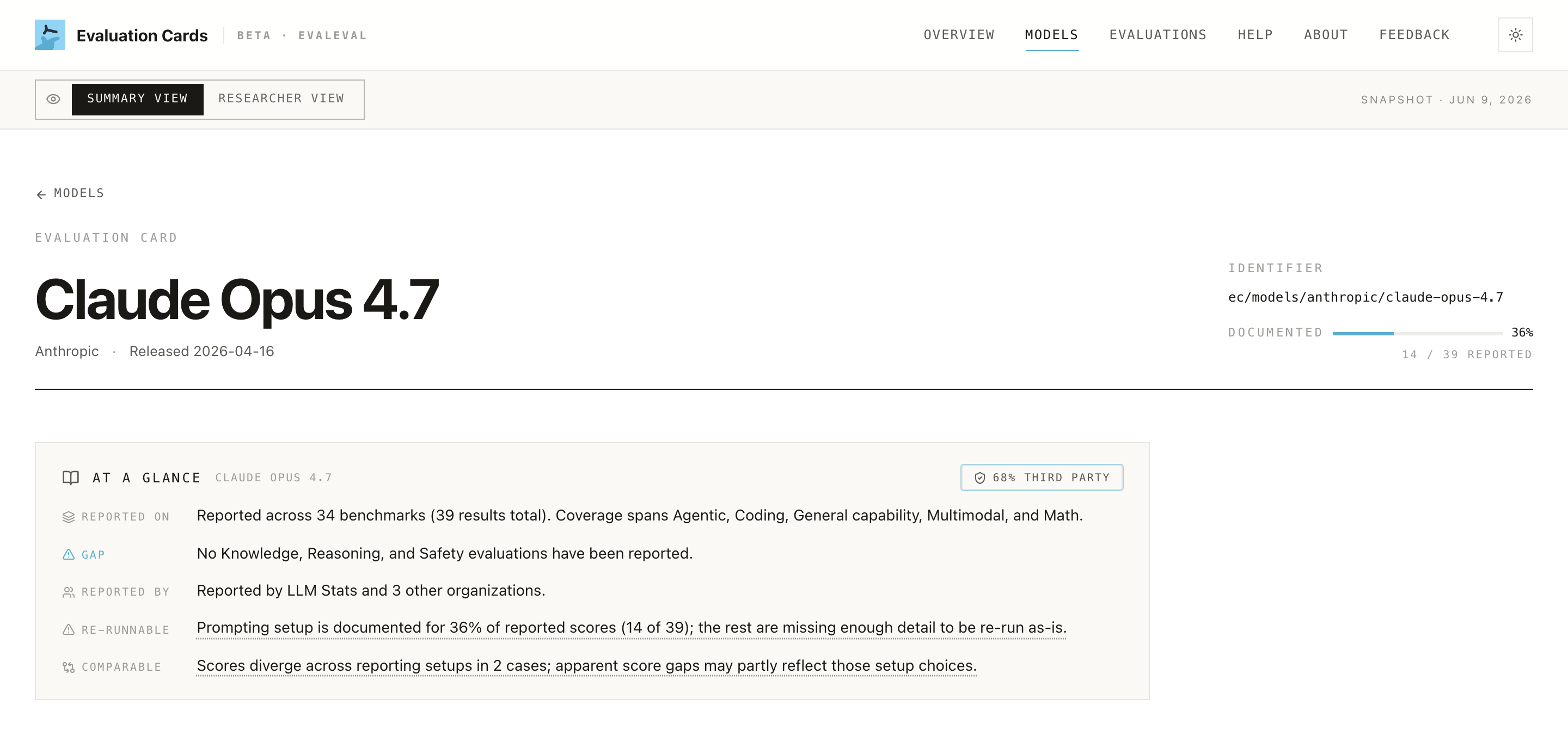
4. Is the comparison even valid? The Comparability signal flags when two scores on the "same" benchmark used different splits, metrics, or units. "Beats the competition" headlines frequently fail this test.
5. Was the relevant area tested at all? Check §2 Benchmark coverage. If a safety/robustness claim has no corresponding evaluation, the absence is your story.

Finding who reported what (sourcing)
Every score is attributed to its source document and reporting organization. Use the Evaluations page to explore a benchmark family and see which organizations reported results, and the model page's §4 to see the source harness behind each number.
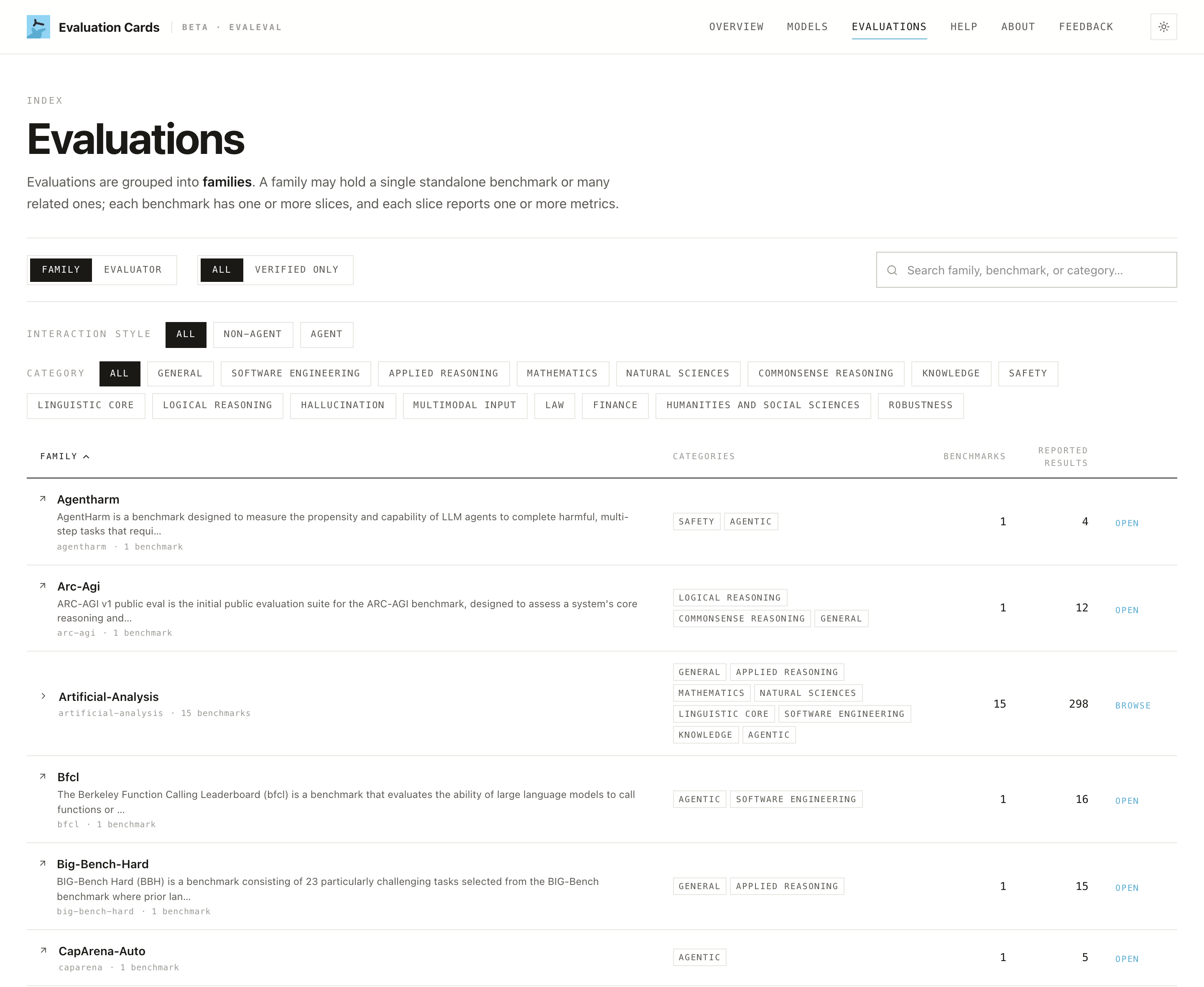
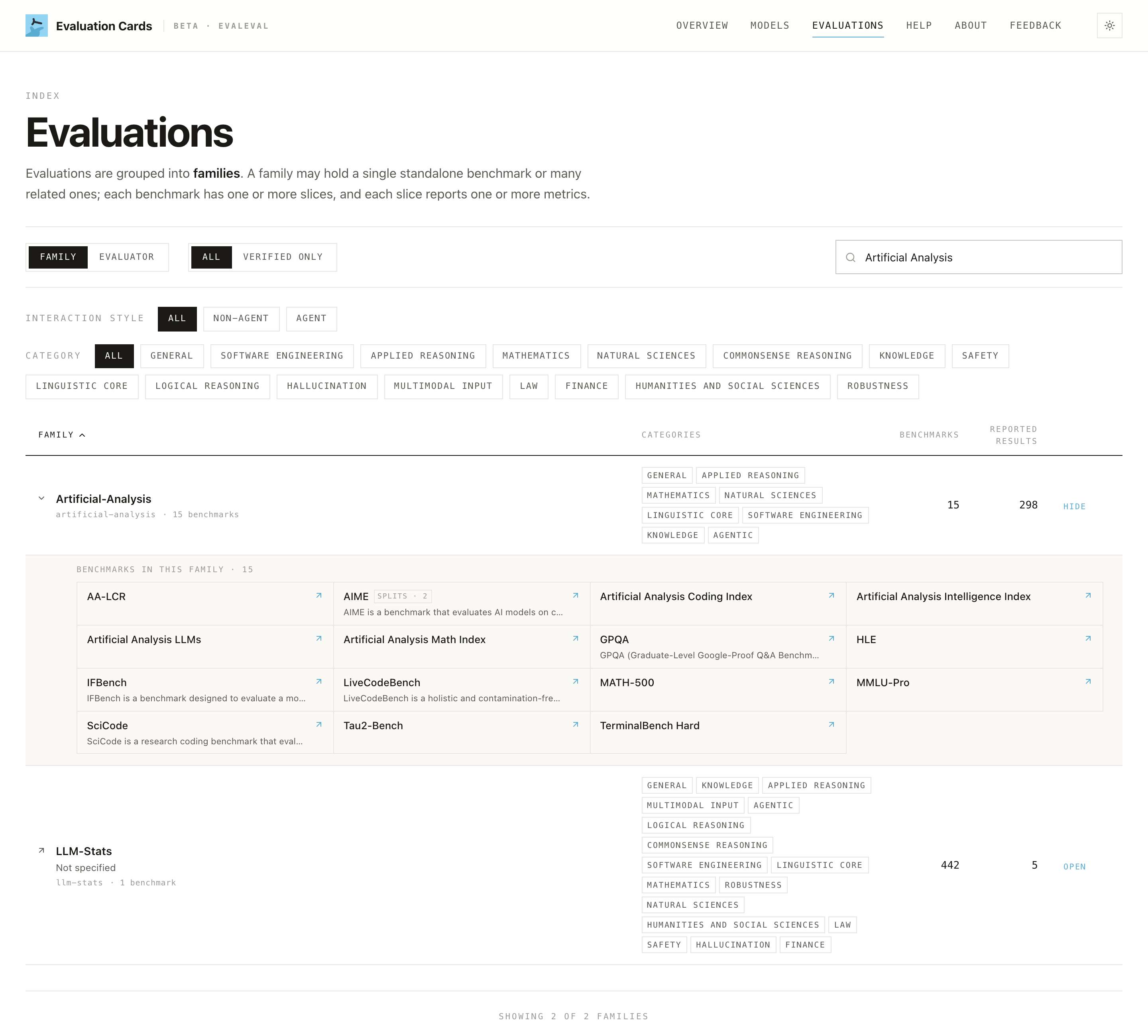
This lets you write "according to [organization], reported in [source]" rather than "the company says."
Citing it correctly
- Cite the snapshot. Every page is dated; the corpus is versioned and not retroactively edited. Write: "per Evaluation Cards, snapshot [date]."
- Use the stable identifier. Each model has an ID like
ec/models/anthropic/claude-opus-4.7. Link the page directly. - Attribute the evaluator, not just the model: "a third-party result reported by [org]" vs "the developer's own reported result."
- Quote the number with its context: the split/metric and whether it's directly comparable.
Overclaiming traps to avoid
| Trap | Better framing |
|---|---|
| "Model X is the best/safest." | "Model X reports the highest self-reported score on [benchmark]; there are no independent results for this in the corpus." |
| Reporting a blank as a failure. | A blank means not reported, not zero. Say "no evaluation was reported." |
| "Model A beats Model B." | Check Comparability first; different setups can make the comparison invalid. |
| Citing a launch blog as the source. | Cite the attributed evaluation + reporting organization + snapshot date. |
| Treating one snapshot as permanent. | Numbers change; date your claim. |
A note on independence
The most defensible AI-performance reporting distinguishes the developer's own numbers from independent ones. The §3 "Who reports what" view makes that distinction in one glance, and a category that is entirely first-party is exactly where a careful reporter adds "self-reported, not independently verified."
➡️ Related: Policymakers (governance framing) · General public (plain-language explainer).